 Информационный бюллетень OVHcloud за июнь Ежемесячный обзор всех новинок OVHcloud, включая анонсы продуктов, новый контент, предстоящие события и многое другое! Базы данных для Valkey Представляем наше последнее дополнение к управляемым базам данных OVHcloud: Valkey! Наши управляемые службы баз данных берут на себя все заботы — от настройки и обслуживания до резервного копирования, безопасности и масштабируемости, — чтобы вы могли в полной мере воспользоваться преимуществами Valkey без лишних хлопот. Предоставьте своим пользователям более удобную работу в Интернете благодаря более быстрой загрузке, оптимизированной обработке очередей и производительности анализа в реальном времени us.ovhcloud.com/public-cloud/valkey/ Расположение новых локальных зон Мы рады сообщить, что наши новейшие локальные зоны в США теперь доступны в Сент-Луисе! Локальные зоны расширяют охват инфраструктуры OVHcloud, размещая вычислительную мощность и хранилище данных ближе к источникам данных. Ускоряйте рост бизнеса, оптимизируя доступ к данным, повышая производительность приложений и используя низкую задержку, оптимальное хранилище и периферийные вычисления. us.ovhcloud.com/public-cloud/local-zone/ Лицензии Windows 2025 на Bare Metal Теперь вы можете заказать лицензии Windows 2025 на наших серверах Bare Metal! Испытайте передовую производительность, улучшенную безопасность и расширенные возможности управления, развернув последние версии Windows Server. Откройте новые возможности прямо из панели управления OVHcloud! SaaS встречает ИИ Поскольку облачные платформы, модели с открытым исходным кодом и генеративный ИИ стремительно развиваются, издатели программного обеспечения как услуги (SaaS) находятся на переломном этапе. Внедрение ИИ больше не является стратегическим преимуществом — это необходимость для поставщиков SaaS, чтобы оставаться конкурентоспособными. Прочитайте наш официальный документ «SaaS встречает ИИ», чтобы узнать, как ИИ меняет подход к разработке программного обеспечения, его доставке и пользовательскому опыту. go.us.ovhcloud.com/rs/084-VVV-483/images/OVH-White-SaaS-Meets-AI_2025_v1.pdf Новая статья Forbes Tech Council Новая облачная лихорадка: как ИИ меняет все ИИ меняет наше представление об облачной инфраструктуре. Поскольку компании спешат интегрировать ИИ, поставщикам облачных услуг приходится меняться, чтобы удовлетворить растущий спрос. Изучите идеи из статьи Forbes Technology Council с участием Джеффри Грегора, генерального директора OVHcloud US. Он обсуждает, как ИИ меняет облачную экосистему, ключевые тенденции, за которыми должны следить компании, и стратегии максимизации ценности при управлении затратами и минимизации рисков www.forbes.com/councils/forbestechcouncil/2025/06/04/the-new-cloud-rush-how-ai-is-reshaping-everything/...
Информационный бюллетень OVHcloud за июнь Ежемесячный обзор всех новинок OVHcloud, включая анонсы продуктов, новый контент, предстоящие события и многое другое! Базы данных для Valkey Представляем наше последнее дополнение к управляемым базам данных OVHcloud: Valkey! Наши управляемые службы баз данных берут на себя все заботы — от настройки и обслуживания до резервного копирования, безопасности и масштабируемости, — чтобы вы могли в полной мере воспользоваться преимуществами Valkey без лишних хлопот. Предоставьте своим пользователям более удобную работу в Интернете благодаря более быстрой загрузке, оптимизированной обработке очередей и производительности анализа в реальном времени us.ovhcloud.com/public-cloud/valkey/ Расположение новых локальных зон Мы рады сообщить, что наши новейшие локальные зоны в США теперь доступны в Сент-Луисе! Локальные зоны расширяют охват инфраструктуры OVHcloud, размещая вычислительную мощность и хранилище данных ближе к источникам данных. Ускоряйте рост бизнеса, оптимизируя доступ к данным, повышая производительность приложений и используя низкую задержку, оптимальное хранилище и периферийные вычисления. us.ovhcloud.com/public-cloud/local-zone/ Лицензии Windows 2025 на Bare Metal Теперь вы можете заказать лицензии Windows 2025 на наших серверах Bare Metal! Испытайте передовую производительность, улучшенную безопасность и расширенные возможности управления, развернув последние версии Windows Server. Откройте новые возможности прямо из панели управления OVHcloud! SaaS встречает ИИ Поскольку облачные платформы, модели с открытым исходным кодом и генеративный ИИ стремительно развиваются, издатели программного обеспечения как услуги (SaaS) находятся на переломном этапе. Внедрение ИИ больше не является стратегическим преимуществом — это необходимость для поставщиков SaaS, чтобы оставаться конкурентоспособными. Прочитайте наш официальный документ «SaaS встречает ИИ», чтобы узнать, как ИИ меняет подход к разработке программного обеспечения, его доставке и пользовательскому опыту. go.us.ovhcloud.com/rs/084-VVV-483/images/OVH-White-SaaS-Meets-AI_2025_v1.pdf Новая статья Forbes Tech Council Новая облачная лихорадка: как ИИ меняет все ИИ меняет наше представление об облачной инфраструктуре. Поскольку компании спешат интегрировать ИИ, поставщикам облачных услуг приходится меняться, чтобы удовлетворить растущий спрос. Изучите идеи из статьи Forbes Technology Council с участием Джеффри Грегора, генерального директора OVHcloud US. Он обсуждает, как ИИ меняет облачную экосистему, ключевые тенденции, за которыми должны следить компании, и стратегии максимизации ценности при управлении затратами и минимизации рисков www.forbes.com/councils/forbestechcouncil/2025/06/04/the-new-cloud-rush-how-ai-is-reshaping-everything/...
 В рамках своего глобального расширения инфраструктуры THE.Hosting объявляет о запуске новой локации — Индия. Дата-центр расположен в Нью-Дели, одном из крупнейших телекоммуникационных узлов региона. Надежная связь, низкая задержка и отличная связь со странами Азии делают этот сайт прекрасным выбором для проектов, ориентированных на Южную Азию. Наши новые виртуальные серверы в Индии изначально оснащены мощными процессорами Intel Xeon Gold 6248 и скоростью порта 1 Гбит/с, что гарантирует максимальную производительность для ваших проектов. Предварительные заказы на виртуальные серверы уже открыты — за 96 часов до официального запуска. Ранние клиенты получают скидку 50% при использовании промокода. Промокод: INDIA50Действителен до: 28 июня 2025 г., 23:59 (UTC+3) Где ввести: в разделе «Корзина», под суммой заказа THE.Hosting — стабильность и надежность для ваших проектов по всему миру. https://the.hosting...
В рамках своего глобального расширения инфраструктуры THE.Hosting объявляет о запуске новой локации — Индия. Дата-центр расположен в Нью-Дели, одном из крупнейших телекоммуникационных узлов региона. Надежная связь, низкая задержка и отличная связь со странами Азии делают этот сайт прекрасным выбором для проектов, ориентированных на Южную Азию. Наши новые виртуальные серверы в Индии изначально оснащены мощными процессорами Intel Xeon Gold 6248 и скоростью порта 1 Гбит/с, что гарантирует максимальную производительность для ваших проектов. Предварительные заказы на виртуальные серверы уже открыты — за 96 часов до официального запуска. Ранние клиенты получают скидку 50% при использовании промокода. Промокод: INDIA50Действителен до: 28 июня 2025 г., 23:59 (UTC+3) Где ввести: в разделе «Корзина», под суммой заказа THE.Hosting — стабильность и надежность для ваших проектов по всему миру. https://the.hosting...
 Призыв к цифровой автономии громче, чем когда-либо. В мире, где ИТ-инфраструктура становится все более сложной, потребность в контроле, прозрачности и владении продолжает расти. В Worldstream мы считаем, что есть лучший путь. Никаких непонятных экосистем или излишеств функций, но инфраструктура, которая понятна и управляема. Вот почему сегодня мы представляем наше обновленное направление: с четким фокусом и свежим внешним видом, но теми же проверенными принципами, которые вы ожидаете от нас — масштабируемая европейская инфраструктура, построенная на самоуправляемых центрах обработки данных, без ненужной сложности. Надежный IT. Никаких сюрпризов. Вы уже можете увидеть наш новый визуальный образ на сайте worldstream.com, а вскоре он появится в наших электронных письмах, на клиентском портале и в других сообщениях. www.worldstream.com/en/
Призыв к цифровой автономии громче, чем когда-либо. В мире, где ИТ-инфраструктура становится все более сложной, потребность в контроле, прозрачности и владении продолжает расти. В Worldstream мы считаем, что есть лучший путь. Никаких непонятных экосистем или излишеств функций, но инфраструктура, которая понятна и управляема. Вот почему сегодня мы представляем наше обновленное направление: с четким фокусом и свежим внешним видом, но теми же проверенными принципами, которые вы ожидаете от нас — масштабируемая европейская инфраструктура, построенная на самоуправляемых центрах обработки данных, без ненужной сложности. Надежный IT. Никаких сюрпризов. Вы уже можете увидеть наш новый визуальный образ на сайте worldstream.com, а вскоре он появится в наших электронных письмах, на клиентском портале и в других сообщениях. www.worldstream.com/en/ 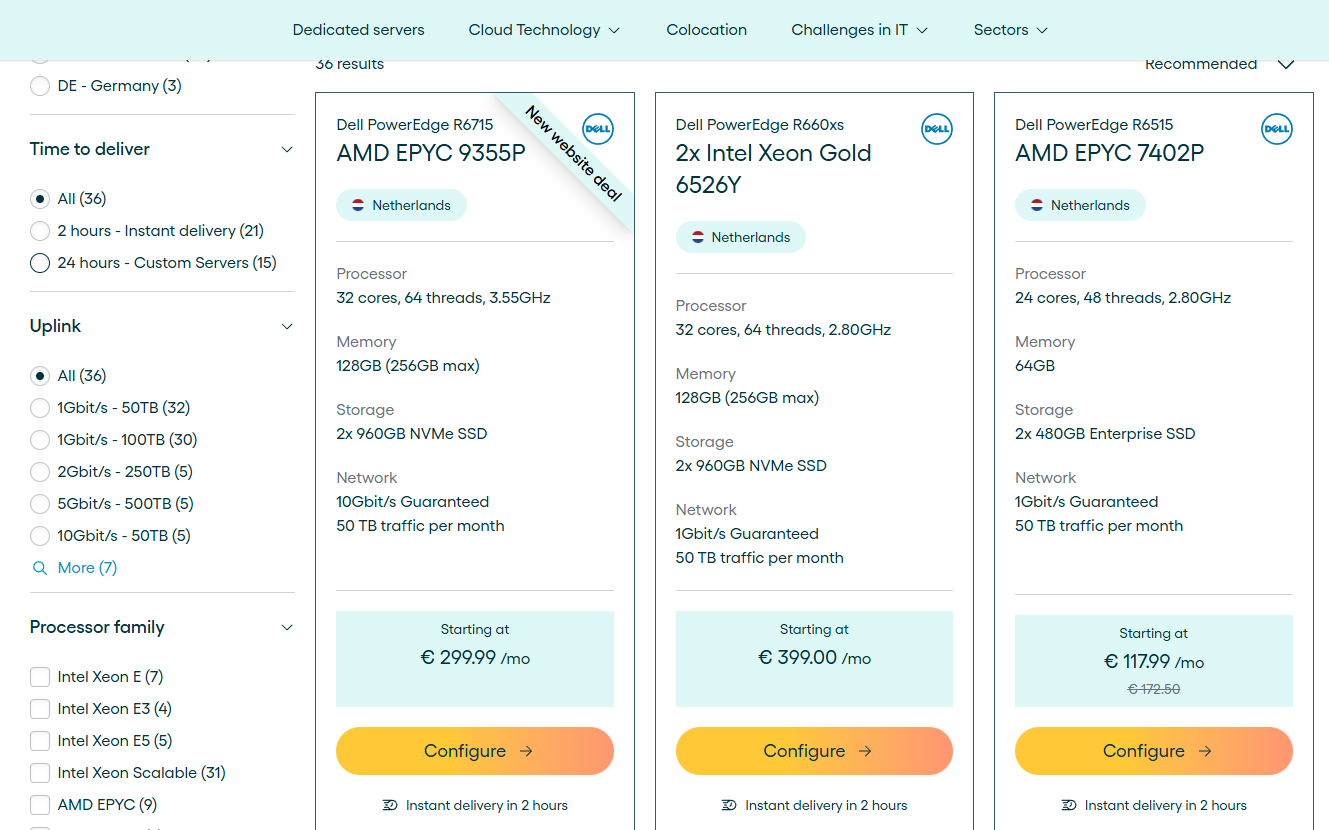 Что это значит для вас? Наряду с новой визуальной идентичностью, новый курс Worldstream означает, что вы получите еще более четкое представление о том, кто мы. Имея четкое направление, мы усердно работаем за кулисами, чтобы расширить наши услуги облачной инфраструктуры. В то же время наш сервис остается неизменным: поддержка 24/7/365, среднее время ответа семь минут и команда, которая всегда готова помочь. Потому что для нас сервис так же важен, как и технология.
Что это значит для вас? Наряду с новой визуальной идентичностью, новый курс Worldstream означает, что вы получите еще более четкое представление о том, кто мы. Имея четкое направление, мы усердно работаем за кулисами, чтобы расширить наши услуги облачной инфраструктуры. В то же время наш сервис остается неизменным: поддержка 24/7/365, среднее время ответа семь минут и команда, которая всегда готова помочь. Потому что для нас сервис так же важен, как и технология.  Мы не просто предлагаем скорость и надежность; мы также обеспечиваем спокойствие. С командой, которая знает, что делает, и которая рядом с вами даже ночью. Вот что означает наш слоган «Solid IT. Никаких сюрпризов» Спасибо за ваше неизменное доверие к Worldstream. Мы с нетерпением ждем возможности формировать цифровой мир вместе с вами. С уважением, От имени всей команды Worldstream, Рубен ван дер Цван Генеральный директор Worldstream...
Мы не просто предлагаем скорость и надежность; мы также обеспечиваем спокойствие. С командой, которая знает, что делает, и которая рядом с вами даже ночью. Вот что означает наш слоган «Solid IT. Никаких сюрпризов» Спасибо за ваше неизменное доверие к Worldstream. Мы с нетерпением ждем возможности формировать цифровой мир вместе с вами. С уважением, От имени всей команды Worldstream, Рубен ван дер Цван Генеральный директор Worldstream...
После «суверенитета данных» и «технологического суверенитета» мы теперь говорим об «операционном суверенитете»: позволяя клиентам выбирать, «кто» управляет технологией и «где» это происходит. Это обещание On-Prem Cloud Platform (OPCP), которое позволит Deep иметь технологии, чтобы стать поставщиком облачных услуг в своих центрах обработки данных в Люксембурге, а также в центрах обработки данных своих собственных клиентов! Для OVHcloud это захватывающая технологическая задача: как упаковать технологию публичного облака (40 продуктов), которую мы разработали, и частное облако (20 платформ), которое мы используем для наших клиентов сегодня, и интегрировать их в OPCP, чтобы иметь возможность развернуть его там, где пожелает клиент, в AirGap или нет, с круглосуточным управлением или без него, работающим на 4 или 4800 серверах, «готовым к сертификации SecNumCloud» или нет. Теперь ясно, что OVHcloud находится на пути к тому, чтобы стать издателем программного обеспечения Public Cloud, включая open source, с поддержкой типа «RedHat», но также с возможностью эксплуатации 24/7, если этого пожелает клиент. Мы также хотим позволить европейской экосистеме программного обеспечения интегрироваться с OPCP, чтобы расширить ценностное предложение, которое мы знаем, как предоставить с 3 уровнями суверенитета: данные, техно, операции. Это также возможность для OVHcloud встретиться с новым типом игроков, очень продвинутых в техническом плане, поговорить о предоставляемых ими услугах, их проблемах и посмотреть, как можно продвинуться еще дальше в продуктах и услугах, которые мы хотим/должны предоставлять. Спасибо Deep за это сотрудничество, которое мы в OVHcloud особенно ценим. Это прекрасный пример европейского сотрудничества в облаке, и мы хотели бы видеть его больше в Европе...

 Мы любили Яндекс Метрику. Правда, любили. Издалека. До того момента, пока не поставили её себе — и через отрицание, гнев, торг и депрессию не приняли простую истину: каждый день мы добровольно скармливаем нашего пользователя конкуренту. А ведь для бизнеса данные о поведении клиентов — это не просто статистика, это то, что превращается в точечные рекламные кампании, персонализированные предложения и в конечном счёте в прибыль. Каждый клик на нашем сайте уходил Яндексу. Каждая сессия пользователя становилась частью огромной аналитической машины, которая затем оборачивалась против нас же — в виде повышения цен на рекламу именно нашей целевой аудитории или дополнительных знаний, помогающих продуктам Яндекса конкурировать с нашими. Тут-то мы и решили: это пора прекратить, надо делать свою метрику, хватит уже этих граблей. Потому что лоб ещё чесался от предыдущих — self-hosted аналитики PostHog, которая нам доставила изрядно танцев с бубнами. Именно оттуда мы, собственно, и перешли на Яндекс Метрику. И это была ошибка. Как всё начиналось Когда мы делали наш первый продукт — L1veStack, нам хотелось сэкономить время и не писать всё с нуля. Поэтому мы взяли несколько хороших опенсорсных систем, которые могли бы закрыть приличную часть функционала. Одна из них — система аналитики PostHog. Она поставляется в двух версиях: облачная и self-hosted. Второе — как раз то, что мы искали, чтобы поставить у себя и не передавать данные на сторону. Мы решили затащить её к себе. Функционал у PostHog — огонь: красиво, удобно, всё на месте. Поставили, встроили, и вроде всё шло нормально. Пока не решили, что мы хотим не просто смотреть цифры, а и сессии пользователей записывать — как в Яндекс Вебвизоре, когда можно посмотреть, что человек на сайте делал. Мы включили эту опцию — и… ничего не заработало. Начали разбираться. Долго и больно. Ковырялись с CORS (Cross-Origin Resource Sharing) и CSRF (Cross-Site Request Forgery) — это те штуки, которые отвечают за безопасность запросов между разными доменами. У нас PostHog был на одном домене, сайт — на другом. Вроде всё правильно делали, но ничего не помогало. Решили попробовать обновиться, потому что с момента установки вышла новая версия. Поставили. О чудо — сессии заработали! Но развалилось всё остальное. Мы застряли в бесконечном цикле: либо сессии не пишутся, либо аналитика ломается. Постоянная нестабильность, баги, конфликты между функциями. Мы поняли, что это не то решение, с которым можно спокойно жить на продакшене. Особенно перед релизом. Время шло, до релиза оставалось всё меньше, и мы поставили Яндекс Метрику. Не потому что хотели, а потому что без аналитики было нельзя. Первое, что сразу резануло, — все данные теперь у Яндекса. Именно этого мы и хотели избежать. Но на старте решили с этим мириться. Посмотрели первые сессии, получили полезные инсайты, кое-что переделали, стало понятнее и удобнее. Но радость была недолгой. Начались проблемы уже у самой Метрики — прямо в интерфейсе висело сообщение, что у них что-то сломалось и отчёты теперь не грузятся. Пользователь аналитики, ты сегодня отдыхаешь.
Мы любили Яндекс Метрику. Правда, любили. Издалека. До того момента, пока не поставили её себе — и через отрицание, гнев, торг и депрессию не приняли простую истину: каждый день мы добровольно скармливаем нашего пользователя конкуренту. А ведь для бизнеса данные о поведении клиентов — это не просто статистика, это то, что превращается в точечные рекламные кампании, персонализированные предложения и в конечном счёте в прибыль. Каждый клик на нашем сайте уходил Яндексу. Каждая сессия пользователя становилась частью огромной аналитической машины, которая затем оборачивалась против нас же — в виде повышения цен на рекламу именно нашей целевой аудитории или дополнительных знаний, помогающих продуктам Яндекса конкурировать с нашими. Тут-то мы и решили: это пора прекратить, надо делать свою метрику, хватит уже этих граблей. Потому что лоб ещё чесался от предыдущих — self-hosted аналитики PostHog, которая нам доставила изрядно танцев с бубнами. Именно оттуда мы, собственно, и перешли на Яндекс Метрику. И это была ошибка. Как всё начиналось Когда мы делали наш первый продукт — L1veStack, нам хотелось сэкономить время и не писать всё с нуля. Поэтому мы взяли несколько хороших опенсорсных систем, которые могли бы закрыть приличную часть функционала. Одна из них — система аналитики PostHog. Она поставляется в двух версиях: облачная и self-hosted. Второе — как раз то, что мы искали, чтобы поставить у себя и не передавать данные на сторону. Мы решили затащить её к себе. Функционал у PostHog — огонь: красиво, удобно, всё на месте. Поставили, встроили, и вроде всё шло нормально. Пока не решили, что мы хотим не просто смотреть цифры, а и сессии пользователей записывать — как в Яндекс Вебвизоре, когда можно посмотреть, что человек на сайте делал. Мы включили эту опцию — и… ничего не заработало. Начали разбираться. Долго и больно. Ковырялись с CORS (Cross-Origin Resource Sharing) и CSRF (Cross-Site Request Forgery) — это те штуки, которые отвечают за безопасность запросов между разными доменами. У нас PostHog был на одном домене, сайт — на другом. Вроде всё правильно делали, но ничего не помогало. Решили попробовать обновиться, потому что с момента установки вышла новая версия. Поставили. О чудо — сессии заработали! Но развалилось всё остальное. Мы застряли в бесконечном цикле: либо сессии не пишутся, либо аналитика ломается. Постоянная нестабильность, баги, конфликты между функциями. Мы поняли, что это не то решение, с которым можно спокойно жить на продакшене. Особенно перед релизом. Время шло, до релиза оставалось всё меньше, и мы поставили Яндекс Метрику. Не потому что хотели, а потому что без аналитики было нельзя. Первое, что сразу резануло, — все данные теперь у Яндекса. Именно этого мы и хотели избежать. Но на старте решили с этим мириться. Посмотрели первые сессии, получили полезные инсайты, кое-что переделали, стало понятнее и удобнее. Но радость была недолгой. Начались проблемы уже у самой Метрики — прямо в интерфейсе висело сообщение, что у них что-то сломалось и отчёты теперь не грузятся. Пользователь аналитики, ты сегодня отдыхаешь. 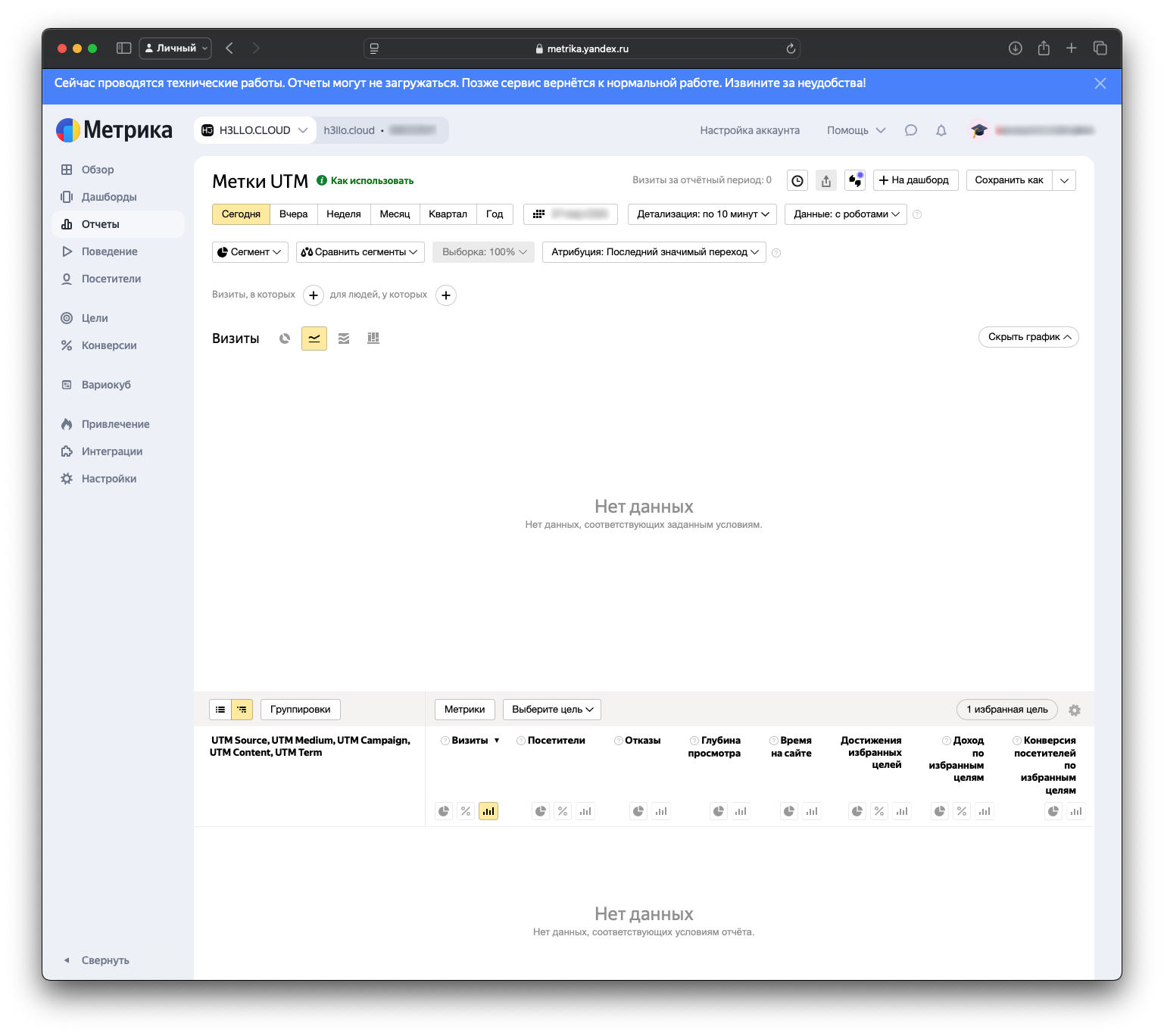 Да ещё проблема блокировки трекеров, пытающихся отследить действия пользователя. Браузеры всё больше встают на защиту приватности пользователей: например, Safari практически полностью блокирует сторонние аналитические системы, да и другие браузеры постепенно движутся в том же направлении. Метрики проседают, мы лишаемся данных о части пользователей. Мы не хотим терять информацию. И отдавать данные компании, которая может использовать их против нас. Остаётся вариант — хранить данные у себя Главный аргумент — контроль. Когда ваши данные гуляют по чужим серверам, всегда есть риск, что они утекут к конкурентам. Например, когда вы используете ту же Яндекс Метрику, происходит следующее:Яндекс видит, какая аудитория посещает ваш сайт, и может повышать для вас цены на рекламу именно этой аудитории (а кто-то же ещё интеграцию с Яндекс Директ настраивает и выручку от транзакции отдаёт, добровольно).Яндекс анализирует, какие функции вашего продукта популярны, и может внедрять похожие в свои сервисы.Яндекс понимает, в какие моменты пользователи покидают ваш сайт, и может использовать эту информацию для улучшения своих продуктов. Представьте, что вы строите инновационный финтех-сервис, а все данные о поведении ваших клиентов уходят в Яндекс Деньги (которые теперь ЮMoney). Или разрабатываете маркетплейс, а информацию о предпочтениях пользователей получает Яндекс Маркет. То есть хранение данных у себя — это не просто технический выбор, это стратегическое конкурентное преимущество. Своя система даёт инструмент для глубокого анализа поведения пользователей без риска раскрытия секретов фирмы. Полный контроль над информацией позволяет быстро реагировать на изменения, обходить блокировки браузеров и использовать самые крутые методы профайлинга. Выгода тут очевидна. Свой продукт не зависит от внешних факторов и обеспечивает конфиденциальность, скорость и стабильность. В общем, мы для себя так сформулировали основную проблему: существующие решения либо передают данные третьим лицам, либо страдают от блокировок браузерных трекеров, либо слишком сложны в настройке и поддержке. Нам нужен был инструмент, который: Хранит все данные на наших серверах.Стабильно работает даже при агрессивной блокировке трекеров.Легко настраивается и не требует команды DevOps для поддержки.Предоставляет всю необходимую функциональность для глубокого анализа. А раз нужен, то его надо сделать. Ну мы и сделали.
Да ещё проблема блокировки трекеров, пытающихся отследить действия пользователя. Браузеры всё больше встают на защиту приватности пользователей: например, Safari практически полностью блокирует сторонние аналитические системы, да и другие браузеры постепенно движутся в том же направлении. Метрики проседают, мы лишаемся данных о части пользователей. Мы не хотим терять информацию. И отдавать данные компании, которая может использовать их против нас. Остаётся вариант — хранить данные у себя Главный аргумент — контроль. Когда ваши данные гуляют по чужим серверам, всегда есть риск, что они утекут к конкурентам. Например, когда вы используете ту же Яндекс Метрику, происходит следующее:Яндекс видит, какая аудитория посещает ваш сайт, и может повышать для вас цены на рекламу именно этой аудитории (а кто-то же ещё интеграцию с Яндекс Директ настраивает и выручку от транзакции отдаёт, добровольно).Яндекс анализирует, какие функции вашего продукта популярны, и может внедрять похожие в свои сервисы.Яндекс понимает, в какие моменты пользователи покидают ваш сайт, и может использовать эту информацию для улучшения своих продуктов. Представьте, что вы строите инновационный финтех-сервис, а все данные о поведении ваших клиентов уходят в Яндекс Деньги (которые теперь ЮMoney). Или разрабатываете маркетплейс, а информацию о предпочтениях пользователей получает Яндекс Маркет. То есть хранение данных у себя — это не просто технический выбор, это стратегическое конкурентное преимущество. Своя система даёт инструмент для глубокого анализа поведения пользователей без риска раскрытия секретов фирмы. Полный контроль над информацией позволяет быстро реагировать на изменения, обходить блокировки браузеров и использовать самые крутые методы профайлинга. Выгода тут очевидна. Свой продукт не зависит от внешних факторов и обеспечивает конфиденциальность, скорость и стабильность. В общем, мы для себя так сформулировали основную проблему: существующие решения либо передают данные третьим лицам, либо страдают от блокировок браузерных трекеров, либо слишком сложны в настройке и поддержке. Нам нужен был инструмент, который: Хранит все данные на наших серверах.Стабильно работает даже при агрессивной блокировке трекеров.Легко настраивается и не требует команды DevOps для поддержки.Предоставляет всю необходимую функциональность для глубокого анализа. А раз нужен, то его надо сделать. Ну мы и сделали. 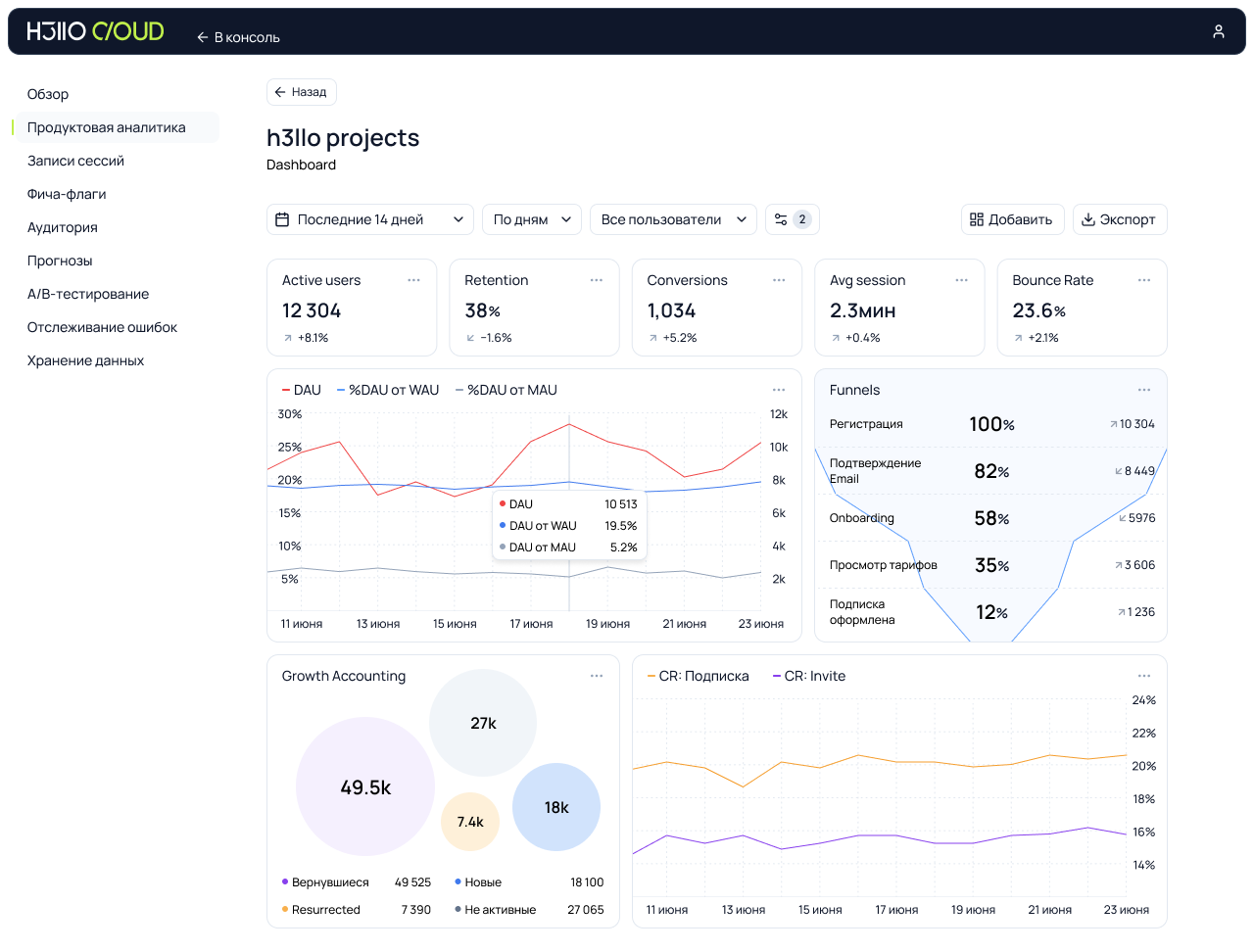 Что под капотом нашей метрики и зачем всё именно так Основной приоритет — полный контроль над данными и лёгкость внедрения. Система предоставляет всё, что нужно для глубокой и точной аналитики: Базовый сбор метаданных: IP, тип устройства, браузер, ОС, разрешение экрана и другие параметры — всё, что помогает понять пользователя.Запись сессий пользователей — аналог Вебвизора: можно воспроизвести действия пользователя на сайте и отследить моменты фрустрации или проблем.Продвинутый профайлинг: события до и после авторизации объединяются в один профиль. Если пользователь несколько раз заходил как гость, а затем авторизовался — вся его история объединяется в единую сессию (если не чистил куки).Feature flags (фича-флаги): гибкое управление функциональностью. Можно включать/отключать фичи для конкретных сегментов пользователей — например, для мобильной аудитории, зарегистрированных в декабре или просто раскатить новую фичу на 5% случайных посетителей.A/B-тестирование: настройка продуктовых гипотез на базе фича-флагов. Можно тестировать разные интерфейсные решения или функционал на разделённых группах пользователей и собирать аналитику.Customer Journey Map (CJM): визуализация пути пользователя — от первого визита до ключевого действия. Видно, где он свернул, где ушёл и как можно улучшить путь.
Что под капотом нашей метрики и зачем всё именно так Основной приоритет — полный контроль над данными и лёгкость внедрения. Система предоставляет всё, что нужно для глубокой и точной аналитики: Базовый сбор метаданных: IP, тип устройства, браузер, ОС, разрешение экрана и другие параметры — всё, что помогает понять пользователя.Запись сессий пользователей — аналог Вебвизора: можно воспроизвести действия пользователя на сайте и отследить моменты фрустрации или проблем.Продвинутый профайлинг: события до и после авторизации объединяются в один профиль. Если пользователь несколько раз заходил как гость, а затем авторизовался — вся его история объединяется в единую сессию (если не чистил куки).Feature flags (фича-флаги): гибкое управление функциональностью. Можно включать/отключать фичи для конкретных сегментов пользователей — например, для мобильной аудитории, зарегистрированных в декабре или просто раскатить новую фичу на 5% случайных посетителей.A/B-тестирование: настройка продуктовых гипотез на базе фича-флагов. Можно тестировать разные интерфейсные решения или функционал на разделённых группах пользователей и собирать аналитику.Customer Journey Map (CJM): визуализация пути пользователя — от первого визита до ключевого действия. Видно, где он свернул, где ушёл и как можно улучшить путь.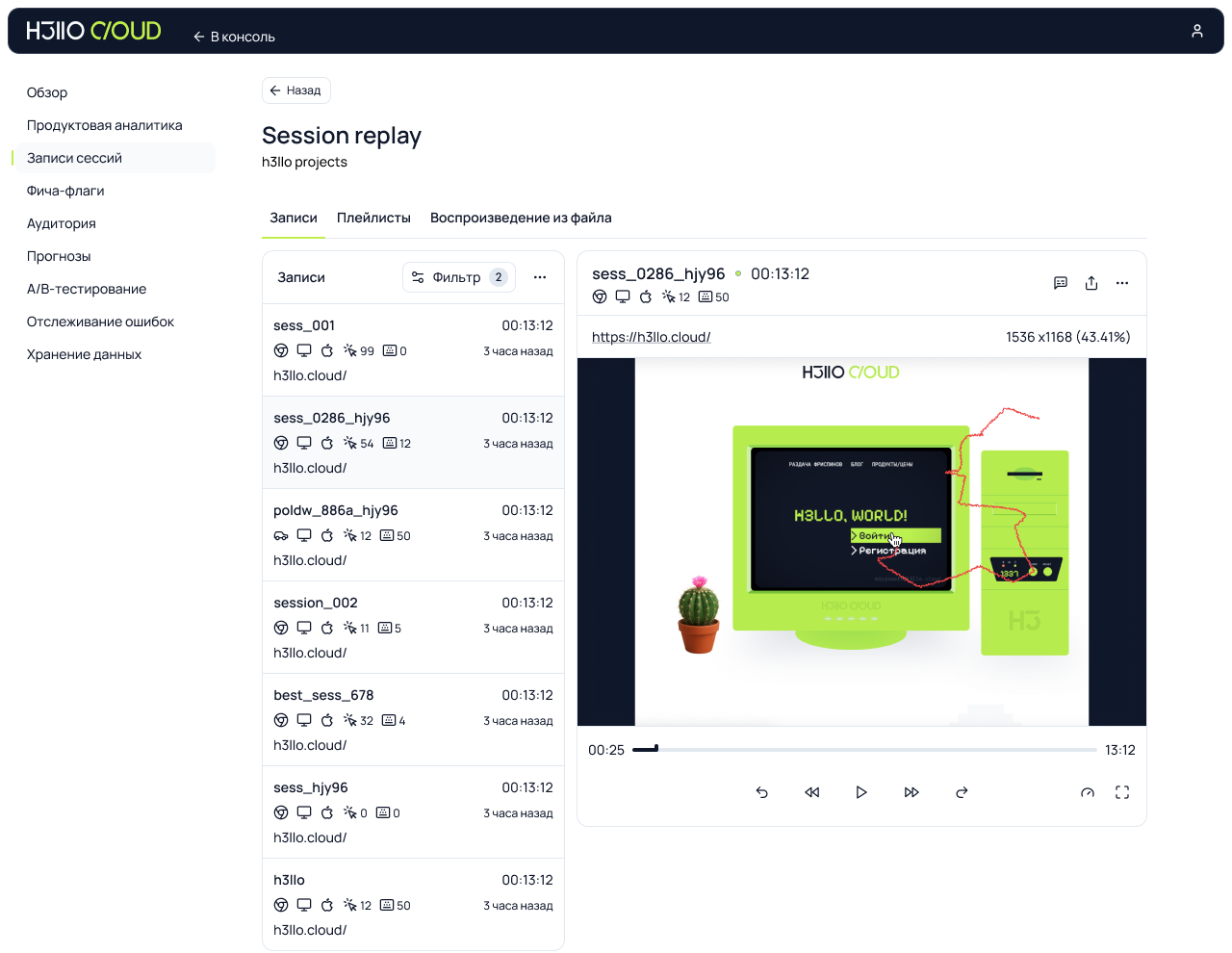 Отдельно расскажу про прогнозный профиль. Это не просто метрика, это чуть-чуть предсказатель. Мы его почти доделали и вот-вот выпустим. Он анализирует поведение пользователя в реальном времени и пытается понять, кто перед нами, ещё до того, как он что-то купил, зарегистрировался или вообще раскрылся. Если человек зашёл на сайт, походил, потыкал кнопки — система собирает сигналы, классифицирует и относит его к одной из поведенческих групп. Похож на тех, кто чаще возвращается? Или на тех, кто сливается после третьего шага? А может, это «быстрый покупатель» и ему нужно меньше отвлечений и больше CTA? Зачем это нужно: чтобы реагировать не постфактум, а прямо по ходу. Подсвечивать нужный сценарий, менять интерфейс, не дожидаясь оттока. Это уже не просто аналитика, а инструмент персонализации и адаптивного интерфейса. Работает он на базе простых ML-моделей, которые дообучаются по мере накопления исторических данных. Всё быстро и с каждым шагом всё точнее. Архитектура с прицелом на будущее С самого начала мы собирали систему с прицелом на простоту, скорость и масштабируемость. Поэтому — микросервисная архитектура, язык Go и только проверенные Open Source компоненты (и то — по минимуму). Всё летает, не ломается и легко разворачивается. Каждый компонент упакован в контейнер: всё разворачивается через Docker Compose или Helm Chart. Установить на собственные серверы можно за 3–4 клика. А при размещении у нас — вообще в один. Интеграция тоже продумана: трекер можно поставить на тот же домен, что и основное приложение. Поэтому он не определяется браузером как сторонний и не блокируется. В архитектуре: REST API принимает данные с фронта;Микросервис записывает сессии пользователей;Работает система профилирования и объединения данных до и после авторизации;Админка построена на GraphQL;Для интеграции на фронте — SDK для React (Next.js). Между сервисами данные передаются по gRPC — это быстрее, надёжнее и стабильнее, чем классический HTTP. Снаружи этого не видно, но именно это делает систему живучей и быстрой даже под нагрузкой. Для админки — отдельный GraphQL-микросервис. Он общается только с внутренними компонентами и не торчит наружу. Всё, что касается настройки фича-флагов, A/B-тестов, CJM и просмотра сессий, — делается через него. Это повышает безопасность: административная логика отделена и не доступна извне. Всю систему мы собрали на проверенных Open Source компонентах: Postgres — для хранения структурированных данных, Redis — для кеширования, Kafka — для обмена сообщениями, ClickHouse — для аналитики. Никаких закрытых зависимостей или скрытых ограничений. Сразу внедрили инструменты наблюдаемости — LGTM-стек (Loki, Grafana, Tempo, Mimir). Это позволяет отслеживать состояние системы, трассировать запросы и анализировать логи — всё прозрачно и под контролем. В общем, получилось решение, которое легко разворачивается, стабильно работает и масштабируется вместе с бизнесом.
Отдельно расскажу про прогнозный профиль. Это не просто метрика, это чуть-чуть предсказатель. Мы его почти доделали и вот-вот выпустим. Он анализирует поведение пользователя в реальном времени и пытается понять, кто перед нами, ещё до того, как он что-то купил, зарегистрировался или вообще раскрылся. Если человек зашёл на сайт, походил, потыкал кнопки — система собирает сигналы, классифицирует и относит его к одной из поведенческих групп. Похож на тех, кто чаще возвращается? Или на тех, кто сливается после третьего шага? А может, это «быстрый покупатель» и ему нужно меньше отвлечений и больше CTA? Зачем это нужно: чтобы реагировать не постфактум, а прямо по ходу. Подсвечивать нужный сценарий, менять интерфейс, не дожидаясь оттока. Это уже не просто аналитика, а инструмент персонализации и адаптивного интерфейса. Работает он на базе простых ML-моделей, которые дообучаются по мере накопления исторических данных. Всё быстро и с каждым шагом всё точнее. Архитектура с прицелом на будущее С самого начала мы собирали систему с прицелом на простоту, скорость и масштабируемость. Поэтому — микросервисная архитектура, язык Go и только проверенные Open Source компоненты (и то — по минимуму). Всё летает, не ломается и легко разворачивается. Каждый компонент упакован в контейнер: всё разворачивается через Docker Compose или Helm Chart. Установить на собственные серверы можно за 3–4 клика. А при размещении у нас — вообще в один. Интеграция тоже продумана: трекер можно поставить на тот же домен, что и основное приложение. Поэтому он не определяется браузером как сторонний и не блокируется. В архитектуре: REST API принимает данные с фронта;Микросервис записывает сессии пользователей;Работает система профилирования и объединения данных до и после авторизации;Админка построена на GraphQL;Для интеграции на фронте — SDK для React (Next.js). Между сервисами данные передаются по gRPC — это быстрее, надёжнее и стабильнее, чем классический HTTP. Снаружи этого не видно, но именно это делает систему живучей и быстрой даже под нагрузкой. Для админки — отдельный GraphQL-микросервис. Он общается только с внутренними компонентами и не торчит наружу. Всё, что касается настройки фича-флагов, A/B-тестов, CJM и просмотра сессий, — делается через него. Это повышает безопасность: административная логика отделена и не доступна извне. Всю систему мы собрали на проверенных Open Source компонентах: Postgres — для хранения структурированных данных, Redis — для кеширования, Kafka — для обмена сообщениями, ClickHouse — для аналитики. Никаких закрытых зависимостей или скрытых ограничений. Сразу внедрили инструменты наблюдаемости — LGTM-стек (Loki, Grafana, Tempo, Mimir). Это позволяет отслеживать состояние системы, трассировать запросы и анализировать логи — всё прозрачно и под контролем. В общем, получилось решение, которое легко разворачивается, стабильно работает и масштабируется вместе с бизнесом. 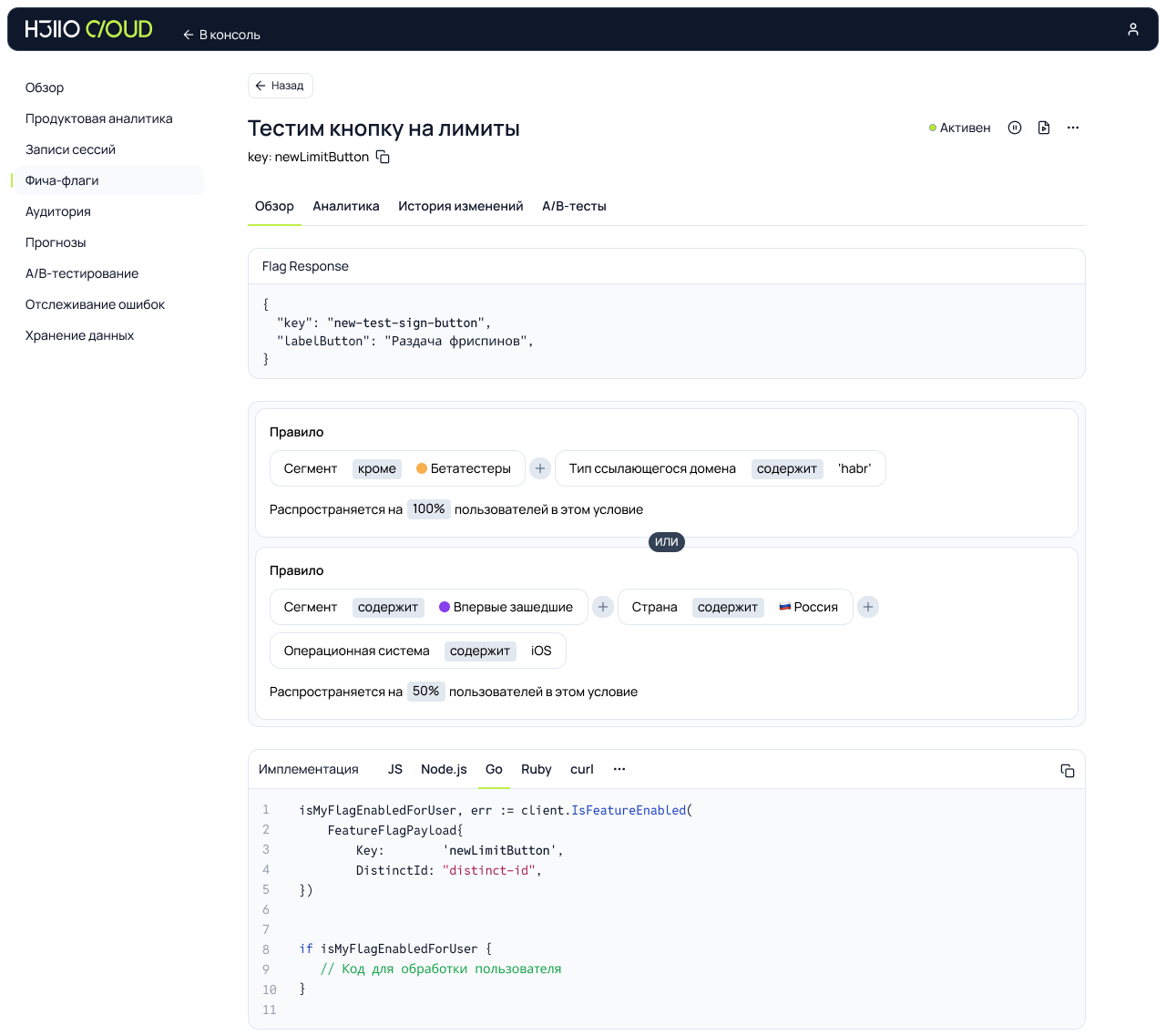 Вайб-кодинг: нейросети в разы ускорили нам разработку Разработка такой системы вручную — это долго и дорого. Если собрать команду из 2–3 бэкендеров, 2 фронтендеров, DevOps и тимлида, то даже на минимальный MVP уйдёт полтора-два месяца плотной работы. Именно так это делалось бы год-полтора назад — без нейросетей, с написанием всего кода вручную. И затраты на разработку вряд ли оправдали бы себя — проще было бы просто оформить подписку на готовый платный сервис. С появлением вайб-кодинга всё изменилось. Прототип мы собрали примерно за неделю силами одного разработчика (меня), и уже на второй неделе система имела рабочий функционал. Здесь важный момент: нужно давать нейросети чёткие инструкции, иначе она начнёт улетать в своих «фантазиях» и понапишет лишнее. Тут не сработает принцип «сделай по лучшим практикам»: получится раздутый проект с размытой логикой и десятками лишних слоёв (не факт, что работающих). В первом подходе прототип был размером в полмиллиона строк кода, с гигантской, размазанной по пяти слоям системой и стоил нам 200 долларов. Я смотрел на всё это и офигевал от того, что она умеет и сколько сразу тратит денег. Во втором подходе я стал прямо пошагово вести нейросеть — ставить больше маленьких задач, давать меньше свободы, то есть использовал такой нейромикроменеджмент. Сначала просил нейросеть составить описание проекта и технические требования, потом сгенерировать моковую реализацию, затем — тесты, и только после этого — рабочий код. Всё руками ревьюил, дорабатывал. Иногда приходилось вообще всё сносить под ноль и перегенерировать заново. Кодовая база сократилась в разы, функциональность стабилизировалась. С каждой итерацией ТЗ конкретизировалось, и нейросеть предлагала всё более эффективные решения. В итоге код стал проще, компактнее и логика — такая, как если бы ты писал сам. Что в результате получилось Это рабочая аналитическая система, которая включает примерно всё, что нужно для глубокого понимания пользователей: Базовый сбор метаданных — то же самое, что собирает Яндекс Метрика: IP-адрес, данные о браузере, тип устройства, разрешение экрана.Запись сессий — полноценный аналог Вебвизора, позволяющий воссоздать каждое действие пользователя на сайте.Продвинутый профайлинг — объединение данных о пользователе до и после авторизации, что решает извечную проблему «потери» посетителя при логине.Фича-флаги — включение или отключение функций для разных групп пользователей без необходимости деплоить новую версию.A/B-тестирование — инструменты для проверки продуктовых гипотез с детальной аналитикой результатов.Customer Journey Map (CJM) — визуализация пути клиента с выявлением точек отказа и затруднений на каждом этапе воронки. Особое внимание мы уделили именно профайлингу и CJM, поскольку эти инструменты позволяют не просто собирать данные, а действительно понимать поведение пользователей и принимать продуктовые решения на основе реальных паттернов. В разработке находится система прогнозного профиля (уже почти готова). Она позволит группировать схожих пользователей и предсказывать их поведение в самом начале сессии. В чём мы круче конкурентов Про Яндекс Метрику я уже много сказал. Добавлю ещё про PostHog: он требует отдельного домена, 4 vCPU, 16 Гб ОЗУ и 30 Гб диска. Установка долгая, несмотря на контейнеры и собственный инсталлятор. При трафике выше 50 тысяч пользователей в сутки начинаются проблемы с производительностью. Собственно, для наглядности сведу всё в таблицу:
Вайб-кодинг: нейросети в разы ускорили нам разработку Разработка такой системы вручную — это долго и дорого. Если собрать команду из 2–3 бэкендеров, 2 фронтендеров, DevOps и тимлида, то даже на минимальный MVP уйдёт полтора-два месяца плотной работы. Именно так это делалось бы год-полтора назад — без нейросетей, с написанием всего кода вручную. И затраты на разработку вряд ли оправдали бы себя — проще было бы просто оформить подписку на готовый платный сервис. С появлением вайб-кодинга всё изменилось. Прототип мы собрали примерно за неделю силами одного разработчика (меня), и уже на второй неделе система имела рабочий функционал. Здесь важный момент: нужно давать нейросети чёткие инструкции, иначе она начнёт улетать в своих «фантазиях» и понапишет лишнее. Тут не сработает принцип «сделай по лучшим практикам»: получится раздутый проект с размытой логикой и десятками лишних слоёв (не факт, что работающих). В первом подходе прототип был размером в полмиллиона строк кода, с гигантской, размазанной по пяти слоям системой и стоил нам 200 долларов. Я смотрел на всё это и офигевал от того, что она умеет и сколько сразу тратит денег. Во втором подходе я стал прямо пошагово вести нейросеть — ставить больше маленьких задач, давать меньше свободы, то есть использовал такой нейромикроменеджмент. Сначала просил нейросеть составить описание проекта и технические требования, потом сгенерировать моковую реализацию, затем — тесты, и только после этого — рабочий код. Всё руками ревьюил, дорабатывал. Иногда приходилось вообще всё сносить под ноль и перегенерировать заново. Кодовая база сократилась в разы, функциональность стабилизировалась. С каждой итерацией ТЗ конкретизировалось, и нейросеть предлагала всё более эффективные решения. В итоге код стал проще, компактнее и логика — такая, как если бы ты писал сам. Что в результате получилось Это рабочая аналитическая система, которая включает примерно всё, что нужно для глубокого понимания пользователей: Базовый сбор метаданных — то же самое, что собирает Яндекс Метрика: IP-адрес, данные о браузере, тип устройства, разрешение экрана.Запись сессий — полноценный аналог Вебвизора, позволяющий воссоздать каждое действие пользователя на сайте.Продвинутый профайлинг — объединение данных о пользователе до и после авторизации, что решает извечную проблему «потери» посетителя при логине.Фича-флаги — включение или отключение функций для разных групп пользователей без необходимости деплоить новую версию.A/B-тестирование — инструменты для проверки продуктовых гипотез с детальной аналитикой результатов.Customer Journey Map (CJM) — визуализация пути клиента с выявлением точек отказа и затруднений на каждом этапе воронки. Особое внимание мы уделили именно профайлингу и CJM, поскольку эти инструменты позволяют не просто собирать данные, а действительно понимать поведение пользователей и принимать продуктовые решения на основе реальных паттернов. В разработке находится система прогнозного профиля (уже почти готова). Она позволит группировать схожих пользователей и предсказывать их поведение в самом начале сессии. В чём мы круче конкурентов Про Яндекс Метрику я уже много сказал. Добавлю ещё про PostHog: он требует отдельного домена, 4 vCPU, 16 Гб ОЗУ и 30 Гб диска. Установка долгая, несмотря на контейнеры и собственный инсталлятор. При трафике выше 50 тысяч пользователей в сутки начинаются проблемы с производительностью. Собственно, для наглядности сведу всё в таблицу: 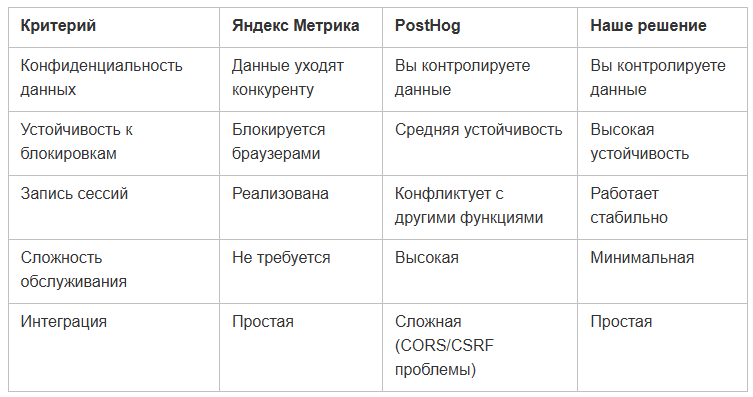 Особенно отмечу тот момент, что благодаря установке нашей системы на стороне пользователя мы обходим блокировки трекеров, так как система становится частью бэкенда и неотличима от основного функционала. Наша модель — это бесплатный продукт без сбора и перепродажи данных. Мы зарабатываем за счёт того, что проще всего запустить систему именно у нас: всё разворачивается в один клик, без лишней возни и администрирования. Такой подход позволяет компаниям любого масштаба получить полный контроль над своими данными без дополнительных расходов, но при этом оставляет возможность для более глубокого сотрудничества. В итоге наш продукт — это универсальное решение для компаний, которые хотят контролировать свои данные и экономить деньги.
Особенно отмечу тот момент, что благодаря установке нашей системы на стороне пользователя мы обходим блокировки трекеров, так как система становится частью бэкенда и неотличима от основного функционала. Наша модель — это бесплатный продукт без сбора и перепродажи данных. Мы зарабатываем за счёт того, что проще всего запустить систему именно у нас: всё разворачивается в один клик, без лишней возни и администрирования. Такой подход позволяет компаниям любого масштаба получить полный контроль над своими данными без дополнительных расходов, но при этом оставляет возможность для более глубокого сотрудничества. В итоге наш продукт — это универсальное решение для компаний, которые хотят контролировать свои данные и экономить деньги. 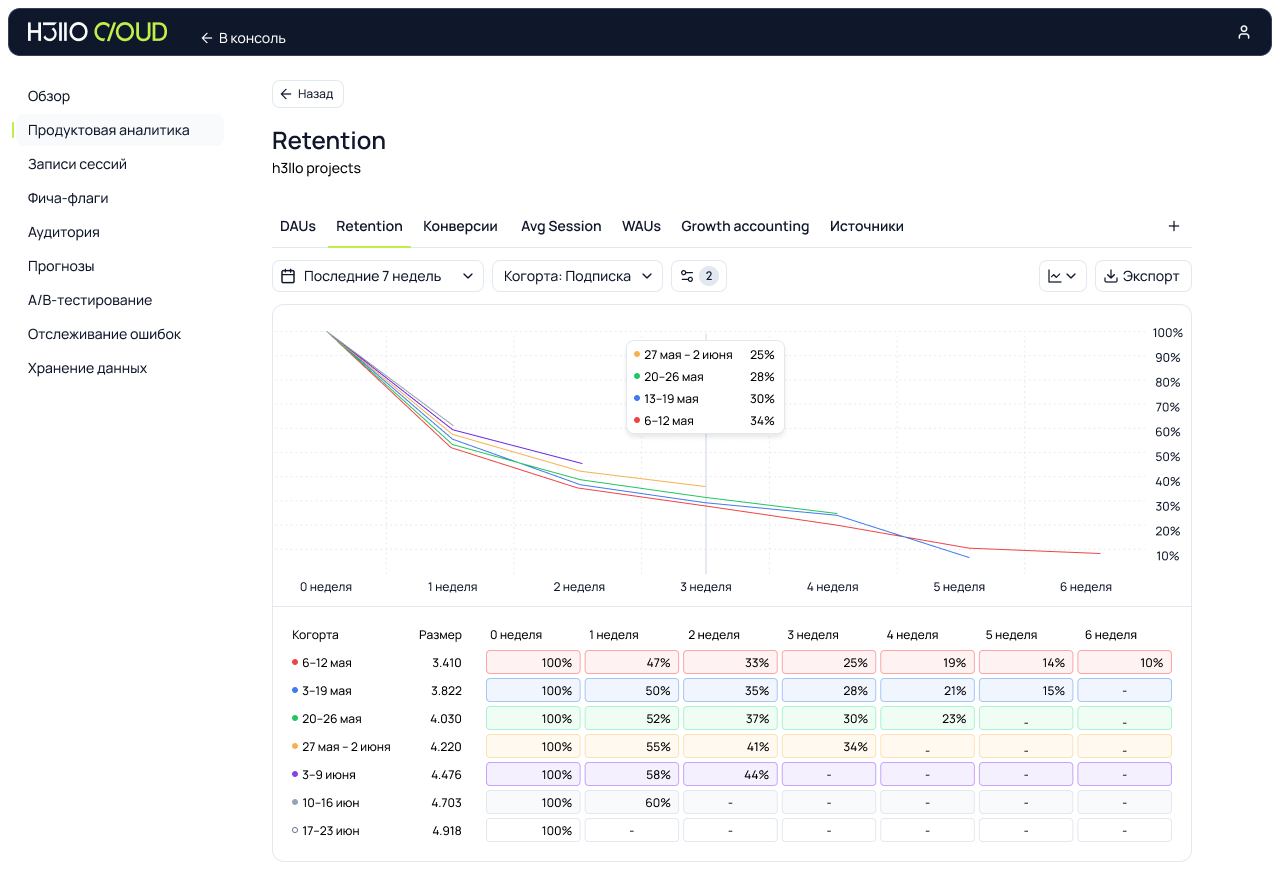 Чему всё это нас научило Вот ключевые уроки, которые мы извлекли: Технологические ограничения внешних сервисов неизбежны. Когда вы используете чужой продукт, вы всегда зависите от решений, принятых его разработчиками. Собственная система даёт полный контроль.Выбор правильного технологического стека критически важен. Go и микросервисная архитектура позволили создать легковесное, но мощное решение, которое легко масштабируется.Нейросети способны радикально ускорить разработку при правильном подходе. Секрет в строгих технических рамках и постоянном тестировании промежуточных результатов.Меньше кода — лучше код. По мере развития проекта мы постоянно оптимизировали архитектуру, уменьшая объём кода и делая его более поддерживаемым. Для разработчиков, которые задумываются о создании подобных систем, наши рекомендации просты: Начинайте с чёткого понимания проблем, которые вы хотите решить.Используйте компактные, хорошо тестируемые компоненты.Не бойтесь применять нейросети, но устанавливайте для них чёткие рамки.Фокусируйтесь на создании ценности для конечных пользователей, а не на технологиях ради технологий. Будущее нашей системы мы видим в развитии прогнозной аналитики, улучшении интерфейса и расширении инструментов для глубокого анализа пользовательского поведения. Мы создали не просто аналитическую платформу, а инструмент, который может стать стратегическим преимуществом для любой компании, заботящейся о своих данных. Контроль над данными — это не роскошь, это необходимость. Не отдавайте своё золото конкурентам. Стройте будущее на основе собственных знаний о своих клиентах. h3llo.cloud/ru...
Чему всё это нас научило Вот ключевые уроки, которые мы извлекли: Технологические ограничения внешних сервисов неизбежны. Когда вы используете чужой продукт, вы всегда зависите от решений, принятых его разработчиками. Собственная система даёт полный контроль.Выбор правильного технологического стека критически важен. Go и микросервисная архитектура позволили создать легковесное, но мощное решение, которое легко масштабируется.Нейросети способны радикально ускорить разработку при правильном подходе. Секрет в строгих технических рамках и постоянном тестировании промежуточных результатов.Меньше кода — лучше код. По мере развития проекта мы постоянно оптимизировали архитектуру, уменьшая объём кода и делая его более поддерживаемым. Для разработчиков, которые задумываются о создании подобных систем, наши рекомендации просты: Начинайте с чёткого понимания проблем, которые вы хотите решить.Используйте компактные, хорошо тестируемые компоненты.Не бойтесь применять нейросети, но устанавливайте для них чёткие рамки.Фокусируйтесь на создании ценности для конечных пользователей, а не на технологиях ради технологий. Будущее нашей системы мы видим в развитии прогнозной аналитики, улучшении интерфейса и расширении инструментов для глубокого анализа пользовательского поведения. Мы создали не просто аналитическую платформу, а инструмент, который может стать стратегическим преимуществом для любой компании, заботящейся о своих данных. Контроль над данными — это не роскошь, это необходимость. Не отдавайте своё золото конкурентам. Стройте будущее на основе собственных знаний о своих клиентах. h3llo.cloud/ru...
 Мы рады, что наш труд был высоко оценен профессиональным сообществом. Наше облако развивается каждый день и прирастает новыми опциями. Впереди у нас еще много работы, а сегодня мы просто порадуемся своим успехам...
Мы рады, что наш труд был высоко оценен профессиональным сообществом. Наше облако развивается каждый день и прирастает новыми опциями. Впереди у нас еще много работы, а сегодня мы просто порадуемся своим успехам...
Добрый день, дорогой читатель. Меня зовут Селезнев Павел, я инженер второй линии поддержки в облачном провайдере Nubes. С каждой новой статьёй я расту в должности, поэтому пишу ещё одну :-) Несколько месяцев назад нам с коллегой поставили задачу: провести сравнительные тесты, чтобы проверить, насколько сильно разогреется видеокарта под нагрузкой при использовании воздуха и диэлектрической жидкости. Об этих тестах я и расскажу в статье, которая должна пролить свет на жизнь GPU в ЦОДе. Предисловие Как понятно из названия статьи, речь пойдёт о жизни GPU в контексте ЦОДа (центра обработки данных), проведённых тестах разных вариантов охлаждения и выводах, к которым пришла наша команда по итогу этих самых тестов и рассуждений. Тестировали мы GPU NVIDIA A16 в течение нескольких дней. На момент написания материала в нашем ЦОДе реализована система охлаждения посредством использования прецизионных кондиционеров, а в качестве хладагента — фреон. Данная система представляет собой большие промышленные шкафы (кондиционеры), которые беспрерывно охлаждают нагретый оборудованием воздух с помощью того самого фреона. На картинке упрощённо показан процесс теплообмена. 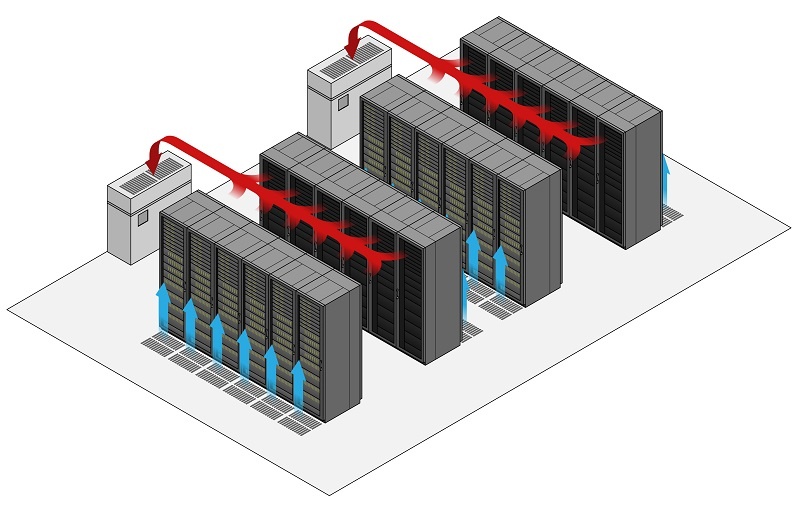 В своей практике я видел и другие системы: водяные кондиционеры, контуры охлаждения на гликоле, чиллерные установки, рассеивающие тепло. О них тоже можно поговорить отдельно. Ещё чуть-чуть и перейдём к тестам Как я и сказал, нам поступила задача проверить рабочие температуры при использовании иммерсионного охлаждения — технологии жидкостного погружения. Основа принципа не сильно отличается от воздушного охлаждения. Движение охлаждающего вещества (хладагента/иммерсионной жидкости/диэлектрической жидкости) происходит также естественно под действием конвекции (движения тёплых, холодных масс) и также с использованием дополнительных насосов в контуре (тепло рассеивается на внешних блоках). Оборудование полностью погружено в жидкость, исключая контакт с внешней средой. Также из особенностей отметим, что для монтажа стенда требуется специальная погружная стойка и сервер. У подобного оборудования предусмотрены специальные отверстия для лучшей циркуляции охлаждающей жидкости. Плюс ко всему требуется дополнительная подготовка видеокарты перед подобным использованием — снятие радиаторов и кулеров (если говорить про любимые многими RTX 4090 и подобные). Из-за этого, прошу заметить, пропадает гарантия на оборудование. Спецификация Так вот, нам дали возможность пощупать что-то новое и провести сравнительный тест охлаждения под нагрузкой, к результатам которого я так долго подводил. Спецификация и сухие цифры ниже. У нас имеются: NVIDIA A16 Архитектура графического процессора: NVIDIA Ampere.Базовая частота чипа графического ускорителя: 1312 МГц.Число универсальных процессоров: 5120.Объём памяти: 64 Гб.Тип памяти: GDDR6.Частота видеопамяти: 12500 МГц.Система охлаждения: пассивная.TDP: 250 Вт.2 среды Воздушная.Жидкостная (в нашем случае был полимер).Софт для нагрузки видеокарты Aida64.Furmark.Hashcat (нагрузили перебором словарей).Нагрузка и наблюдение за картами в течение 4 дней по 24 часа в сутки Самое интересное — иммерсионная жидкость Используется диэлектрическая охлаждающая жидкость, полимер низкой вязкости ДОЖ1.Горючесть 600 градусов в открытом тигле.Температура рабочего диапазона -60С +180С.Срок службы не менее 10 лет. Уровень испаряемости низкий, поэтому подливать не нужно (если система не даст течь).Расчётный механический PUE 1.06. Тесты Скрины по результатам тестов ниже. Воздушное охлаждение
В своей практике я видел и другие системы: водяные кондиционеры, контуры охлаждения на гликоле, чиллерные установки, рассеивающие тепло. О них тоже можно поговорить отдельно. Ещё чуть-чуть и перейдём к тестам Как я и сказал, нам поступила задача проверить рабочие температуры при использовании иммерсионного охлаждения — технологии жидкостного погружения. Основа принципа не сильно отличается от воздушного охлаждения. Движение охлаждающего вещества (хладагента/иммерсионной жидкости/диэлектрической жидкости) происходит также естественно под действием конвекции (движения тёплых, холодных масс) и также с использованием дополнительных насосов в контуре (тепло рассеивается на внешних блоках). Оборудование полностью погружено в жидкость, исключая контакт с внешней средой. Также из особенностей отметим, что для монтажа стенда требуется специальная погружная стойка и сервер. У подобного оборудования предусмотрены специальные отверстия для лучшей циркуляции охлаждающей жидкости. Плюс ко всему требуется дополнительная подготовка видеокарты перед подобным использованием — снятие радиаторов и кулеров (если говорить про любимые многими RTX 4090 и подобные). Из-за этого, прошу заметить, пропадает гарантия на оборудование. Спецификация Так вот, нам дали возможность пощупать что-то новое и провести сравнительный тест охлаждения под нагрузкой, к результатам которого я так долго подводил. Спецификация и сухие цифры ниже. У нас имеются: NVIDIA A16 Архитектура графического процессора: NVIDIA Ampere.Базовая частота чипа графического ускорителя: 1312 МГц.Число универсальных процессоров: 5120.Объём памяти: 64 Гб.Тип памяти: GDDR6.Частота видеопамяти: 12500 МГц.Система охлаждения: пассивная.TDP: 250 Вт.2 среды Воздушная.Жидкостная (в нашем случае был полимер).Софт для нагрузки видеокарты Aida64.Furmark.Hashcat (нагрузили перебором словарей).Нагрузка и наблюдение за картами в течение 4 дней по 24 часа в сутки Самое интересное — иммерсионная жидкость Используется диэлектрическая охлаждающая жидкость, полимер низкой вязкости ДОЖ1.Горючесть 600 градусов в открытом тигле.Температура рабочего диапазона -60С +180С.Срок службы не менее 10 лет. Уровень испаряемости низкий, поэтому подливать не нужно (если система не даст течь).Расчётный механический PUE 1.06. Тесты Скрины по результатам тестов ниже. Воздушное охлаждение 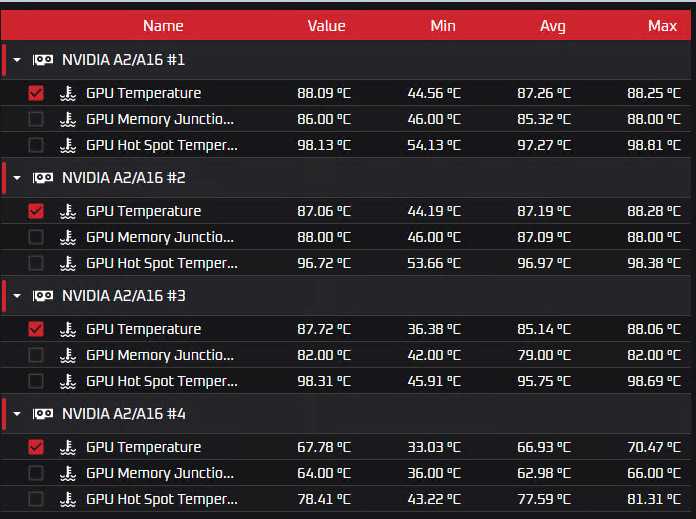
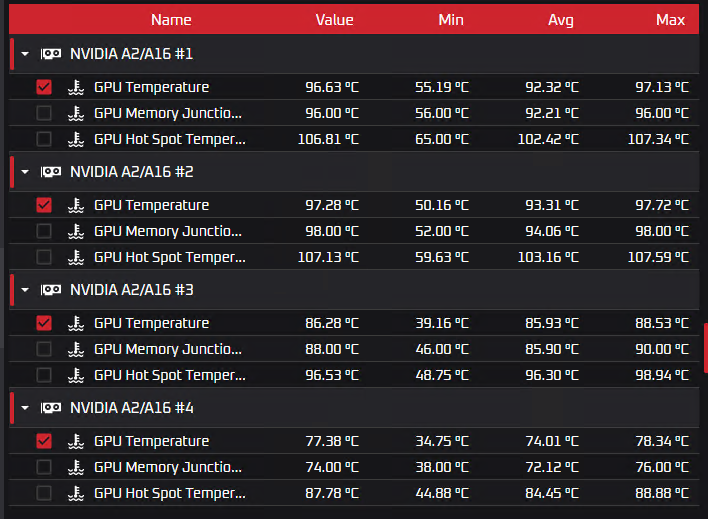
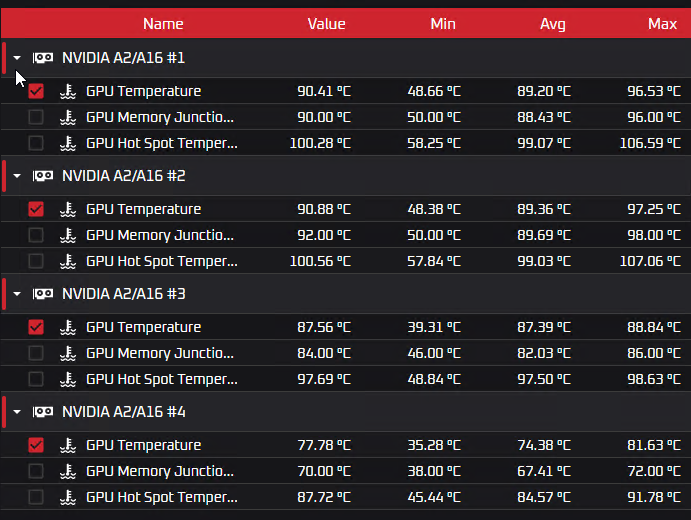
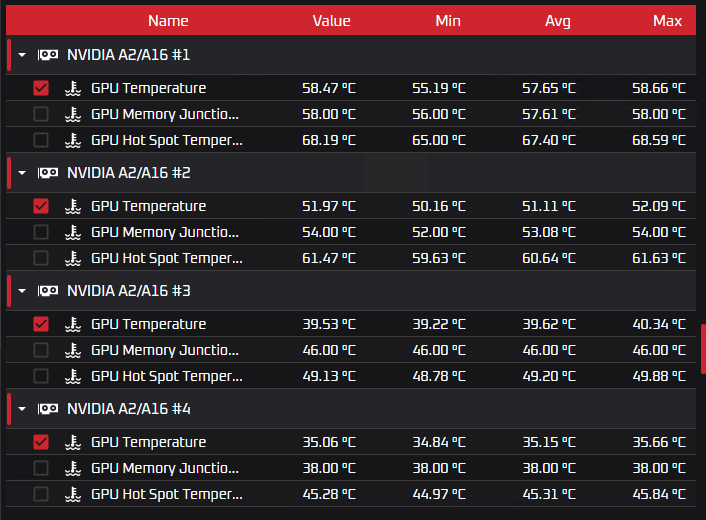 Жидкостное охлаждение
Жидкостное охлаждение 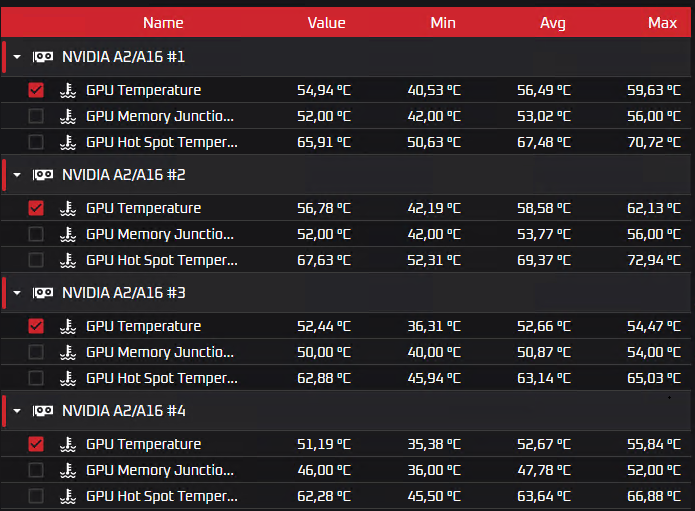
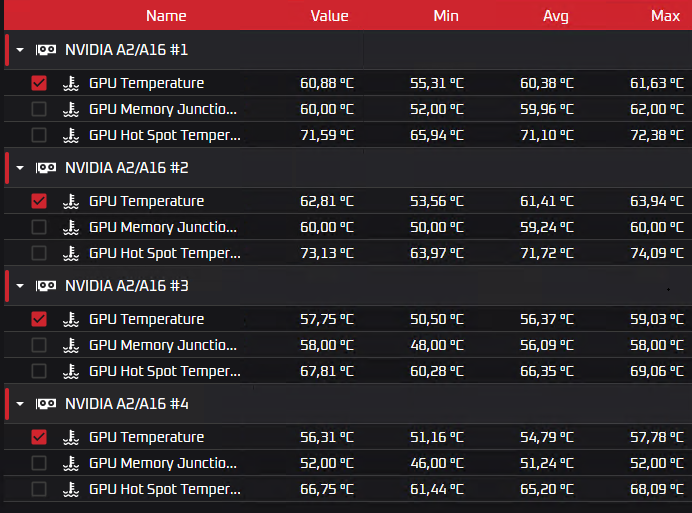
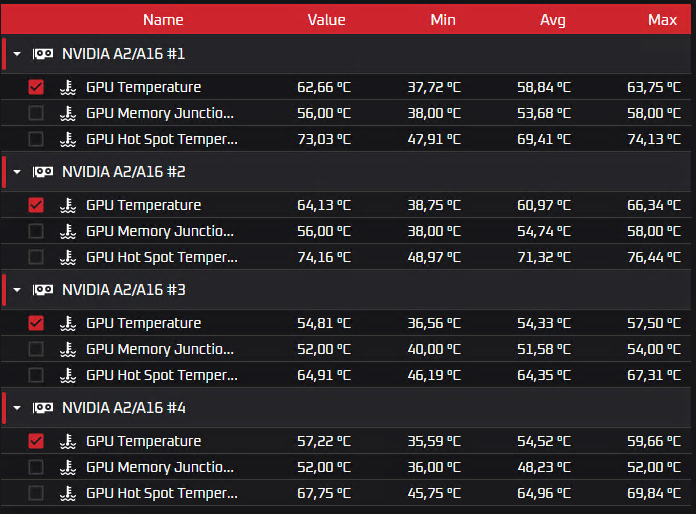
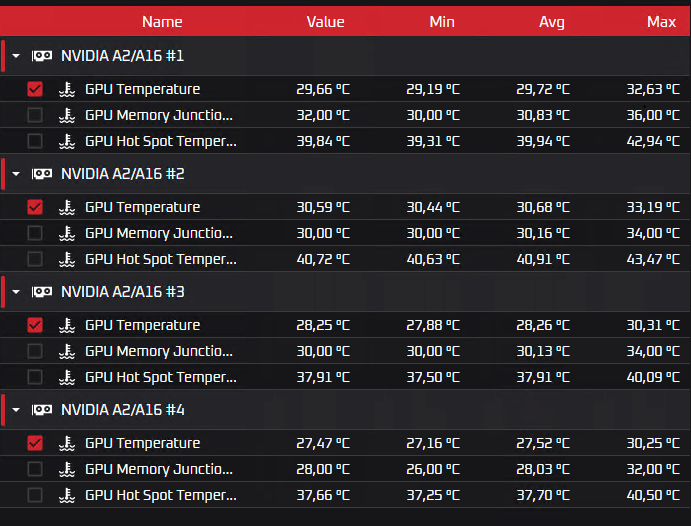 Общая статистика: в таблицу собрал средние значения (то есть среднее по всем четырём ядрам).
Общая статистика: в таблицу собрал средние значения (то есть среднее по всем четырём ядрам). 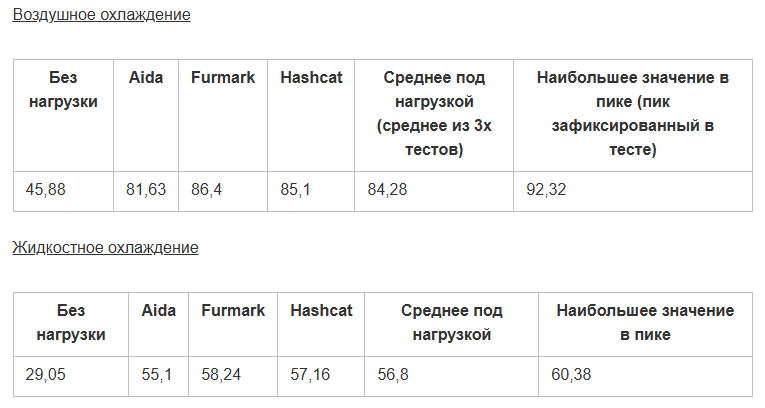 Итоги теста На практике была доказана более высокая эффективность использования жидкостного охлаждения. Зачем оно всё было надо На данный момент технологии ИИ развиваются бурно, и для обучения или использования искусственного интеллекта требуются вычислительные мощности. Получается, что ИИ = GPU. Видеокарты, создание инфраструктуры и её поддержание в рабочем состояние – дорого. Поэтому GPU из облака выглядит довольно «вкусно», особенно предприятиям/компаниям/ИП, которые хотели бы «пощупать» карты в тесте (у нас, например, это 14 дней) или интегрировать ИИ в работу без постройки масштабных комплексов и дополнительных затрат. Так зачем делали тесты-то? Всё ещё непонятно. Раз ресурсы GPU востребованы на рынке, то, если один облачный провайдер хочет конкурировать с другими, в своём арсенале эти карточки обязательно нужно иметь. Nubes хочет предоставлять GPU-as-a-Service в большом количестве. Большое количество графических процессоров – это много тепла и повышенная нагрузка на кондиционеры, которые работают… правильно, от электричества. Оно растёт в цене, следовательно, увеличиваются расходы на эксплуатацию. Жидкостное же охлаждение требует меньше энергии, и это весомая причина рассмотреть такой вариант. Какие выводы мы сделали Иммерсионное охлаждение — лучший холод, что, в свою очередь, увеличивает срок эксплуатации оборудования. Да и ёмкости с минеральным маслом шумят меньше, чем кондиционеры. Ещё один существенный плюс — иммерсионное решение не требует «особой» подготовки места: наличие фальшполов для циркуляции холодных воздушных масс, создание изолированных коридоров, место под кондиционеры. Всё круто, всё здорово, но подходит такой вариант охлаждения не всем, и есть у него ряд существенных «но». Во-первых, как уже было сказано, для использования такого вида охлаждения нужна подготовка видеокарты. Потребуется снятие термоинтерфейсов и системы воздушного охлаждения. Из-за этого теряется гарантия карточки. Для co-location, например, такой вариант не очень подходит. Во-вторых, для иммерсионного охлаждения используются специальные сервера, которые по производительности RAM и CPU уступают дефолтным аналогам. Публичное облако на них построить можно, но вариант не приоритетный. Также погружные стойки, которые мы видели, рассчитаны всего на 26U, то есть на 26 позиций для серверов. Под заказ, конечно, сделают и больше, но стандартное решение у ТК «Связь» именно 26U.
Итоги теста На практике была доказана более высокая эффективность использования жидкостного охлаждения. Зачем оно всё было надо На данный момент технологии ИИ развиваются бурно, и для обучения или использования искусственного интеллекта требуются вычислительные мощности. Получается, что ИИ = GPU. Видеокарты, создание инфраструктуры и её поддержание в рабочем состояние – дорого. Поэтому GPU из облака выглядит довольно «вкусно», особенно предприятиям/компаниям/ИП, которые хотели бы «пощупать» карты в тесте (у нас, например, это 14 дней) или интегрировать ИИ в работу без постройки масштабных комплексов и дополнительных затрат. Так зачем делали тесты-то? Всё ещё непонятно. Раз ресурсы GPU востребованы на рынке, то, если один облачный провайдер хочет конкурировать с другими, в своём арсенале эти карточки обязательно нужно иметь. Nubes хочет предоставлять GPU-as-a-Service в большом количестве. Большое количество графических процессоров – это много тепла и повышенная нагрузка на кондиционеры, которые работают… правильно, от электричества. Оно растёт в цене, следовательно, увеличиваются расходы на эксплуатацию. Жидкостное же охлаждение требует меньше энергии, и это весомая причина рассмотреть такой вариант. Какие выводы мы сделали Иммерсионное охлаждение — лучший холод, что, в свою очередь, увеличивает срок эксплуатации оборудования. Да и ёмкости с минеральным маслом шумят меньше, чем кондиционеры. Ещё один существенный плюс — иммерсионное решение не требует «особой» подготовки места: наличие фальшполов для циркуляции холодных воздушных масс, создание изолированных коридоров, место под кондиционеры. Всё круто, всё здорово, но подходит такой вариант охлаждения не всем, и есть у него ряд существенных «но». Во-первых, как уже было сказано, для использования такого вида охлаждения нужна подготовка видеокарты. Потребуется снятие термоинтерфейсов и системы воздушного охлаждения. Из-за этого теряется гарантия карточки. Для co-location, например, такой вариант не очень подходит. Во-вторых, для иммерсионного охлаждения используются специальные сервера, которые по производительности RAM и CPU уступают дефолтным аналогам. Публичное облако на них построить можно, но вариант не приоритетный. Также погружные стойки, которые мы видели, рассчитаны всего на 26U, то есть на 26 позиций для серверов. Под заказ, конечно, сделают и больше, но стандартное решение у ТК «Связь» именно 26U.  В-третьих, жидкостное охлаждение не исключает необходимость установки внешних блоков для отвода тепла и резервирования электропитания. В общем, вывод такой: технология есть, она эффективная, но далеко не во всех случаях. И нужно взвешивать плюс и минусы, ну и, конечно же, считать выгоду. nubes.ru...
В-третьих, жидкостное охлаждение не исключает необходимость установки внешних блоков для отвода тепла и резервирования электропитания. В общем, вывод такой: технология есть, она эффективная, но далеко не во всех случаях. И нужно взвешивать плюс и минусы, ну и, конечно же, считать выгоду. nubes.ru...
 Представляем ispmanager 6.123: теперь с поддержкой LiteSpeed и встроенным WAF: LiteSpeed — сверхбыстрый веб-сервер, полностью совместимый с Apache-конфигурациями. Ускоряет загрузку сайтов и улучшает Core Web Vitals.WAF — надежная защита от распространённых угроз, таких как SQL-инъекции и XSS. WAF проверяет весь входящий трафик и блокирует подозрительные запросы.Готовы увидеть LiteSpeed и WAF в деле? Вот пара материалов, которые могут пригодиться: Как установить LiteSpeed в ispmanagerКак включить WAF в ispmanagerЦены на лицензии LiteSpeedПодробный обзор возможностей LiteSpeed и WAF в ispmanager Если возникнут вопросы — мы всегда на связи и готовы помочь! Спасибо, что вы с нами, Команда ispmanager...
Представляем ispmanager 6.123: теперь с поддержкой LiteSpeed и встроенным WAF: LiteSpeed — сверхбыстрый веб-сервер, полностью совместимый с Apache-конфигурациями. Ускоряет загрузку сайтов и улучшает Core Web Vitals.WAF — надежная защита от распространённых угроз, таких как SQL-инъекции и XSS. WAF проверяет весь входящий трафик и блокирует подозрительные запросы.Готовы увидеть LiteSpeed и WAF в деле? Вот пара материалов, которые могут пригодиться: Как установить LiteSpeed в ispmanagerКак включить WAF в ispmanagerЦены на лицензии LiteSpeedПодробный обзор возможностей LiteSpeed и WAF в ispmanager Если возникнут вопросы — мы всегда на связи и готовы помочь! Спасибо, что вы с нами, Команда ispmanager...