 HSTQ — это собственное «железо», проверенные дата-центры в Европе, Азии и США и инженеры 24/7, которые доводят запуск до результата. Мы берём на себя перенос и настройку, даём IPMI/KVM, включаем DDoS-защиту и помогаем с ISO — вы сосредотачиваетесь на продукте, а не на инфраструктуре. Если что-то пойдёт не так — действует гарантия возврата в течение 30 дней. Выберите тариф ниже, расскажите о проекте — мы подготовим серверы, проверим производительность и останемся рядом, пока всё стабильно не заработает. Промо — hstq.net/promo.html Вирт. хостинг — $0.99/мес VDS — $1/мес Выделенный сервер — $29.99/мес VPS / VDS NVMe. Локации: NL/DE/RU/UK/USA — hstq.net/vps.html Spark — 2 vCPU / 2 GB / 40 GB NVMe / 10 Gb/s — $9.99/мес Thrust — 4 vCPU / 6 GB / 80 GB NVMe / 10 Gb/s — $19.99/мес Velocity — 8 vCPU / 12 GB / 160 GB NVMe / 10 Gb/s — $39.99/мес Overdrive — 12 vCPU / 24 GB / 320 GB NVMe / 10 Gb/s — $59.99/мес Выделенные серверы (Dedicated) — hstq.net/servers.html Xeon E-2186G / 32 GB / 480 GB SSD / 1 Gbit/s / NL — $99/мес Xeon E-2356G / 64 GB / 1 TB NVMe / 1 Gbit/s / SG — $119/мес 2× Xeon E5-2650v2 / 128 GB / 2×1 TB SSD / 10 Gbit/s / NL — $349/мес Xeon Gold 5218R / 128 GB / 2×1 TB NVMe / 10 Gbit/s / NL/US — $399/мес AMD EPYC 7702P / 128 GB / 2×2 TB NVMe / 25 Gbit/s / NL — $599/мес AMD EPYC 7702P / 128 GB / 2×2 TB NVMe / 40 Gbit/s / NL — $799/мес Аренда IPv4 (подсети): /27 (32 IP) — $49/мес /26 (64 IP) — $79/мес /25 (128 IP) — $99/мес /24 (256 IP) — $169/мес (LoA, WHOIS/PTR, анонс в другой ДЦ) /23 (512 IP) — $299/мес (LoA/WHOIS/PTR, анонс) /22 (1024 IP) — $499/мес (LoA/WHOIS/PTR, анонс) Администрирование (Linux): Эконом — $99/мес (4 ч/мес: обновления, базовая защита, бекапы, 24/7 мониторинг) Стандарт — $199/мес (12 ч/мес: +тюнинг, настройка ПО/фаервола, задачи/скрипты, 24/7 мониторинг) Премиум — $399/мес (30 ч/мес: +архитектура, HA, балансировка, DevOps, аудит безопасности, проактивный 24/7) Администрирование (Windows): Эконом — $199/мес (4 ч/мес, базовые работы и мониторинг) Стандарт — $299/мес (12 ч/мес, тюнинг IIS/ASP.NET, службы, триггеры мониторинга) Премиум — $499/мес (30 ч/мес, архитектура/HA, проактивный 24/7 SRE) Премиум (для любой ОС): шифрование дисков, администрирование хранилищ, геораспределённые сервисы, VPN/прокси. LIR / IP-ресурсы / ASN: Поддержка rDNS вашей сети (любой размер) — $50/мес (собственный DNS-парк) Помощь в получении /24 и регистрации LIR — $500 разово (членские взносы оплачиваются отдельно) Регистрация ASN — $399 разово Поддержка ASN — $199/год (взносы включены) PI /24 (покупка у нас) — $12 500 разово Бонус: при поддержке + регистрации ASN — IPv6 /32 бесплатно, пока активна поддержка ASN. Почему нам доверяют с первого заказа: — Быстрый старт: активация за минуты/часы и понятные SLA. — Прозрачные цены без скрытых условий + гарантия возврата 30 дней. — Поддержка, которая решает, а не «заводит тикет». — Оформление без KYC — быстрее и удобнее, но строго в рамках закона и AUP. Мы не требуем KYC при оформлении, потому что делаем услугу удобной и быстрой. Это не означает «серый» хостинг: мы соблюдаем законы юрисдикций, реагируем на abuse, поддерживаем best-practice (RPKI/IRR, фильтры) и не размещаем запрещённый контент. Наша задача — ускорить запуск, а не нарушать правила. Готовы начать сегодня? Выберите тариф ниже и опишите задачу — подберём конфигурацию, подготовим серверы и поможем с переносом. Если удобнее, напишите нам в Telegram: @hstq_hosting или в чат на сайте. Реквизиты и контакты: Юридическое лицо: BVI HSTQ Hosting quality service Reg. No.: 6949321 Registered Agent: Offshore Incorporations Limited Адрес: 18 Pasea Estate Road, Road Town, Tortola, VG1110, British Virgin Islands Телефон: +1 282-222-8282 E-mail: support@hstq.net, sales@hstq.net Telegram: @hstq_hosting, @hstq_official (новости) Тикет-система: cp.hstq.net → «Поддержка» → «Новый тикет» Сайт: hstq.net...
HSTQ — это собственное «железо», проверенные дата-центры в Европе, Азии и США и инженеры 24/7, которые доводят запуск до результата. Мы берём на себя перенос и настройку, даём IPMI/KVM, включаем DDoS-защиту и помогаем с ISO — вы сосредотачиваетесь на продукте, а не на инфраструктуре. Если что-то пойдёт не так — действует гарантия возврата в течение 30 дней. Выберите тариф ниже, расскажите о проекте — мы подготовим серверы, проверим производительность и останемся рядом, пока всё стабильно не заработает. Промо — hstq.net/promo.html Вирт. хостинг — $0.99/мес VDS — $1/мес Выделенный сервер — $29.99/мес VPS / VDS NVMe. Локации: NL/DE/RU/UK/USA — hstq.net/vps.html Spark — 2 vCPU / 2 GB / 40 GB NVMe / 10 Gb/s — $9.99/мес Thrust — 4 vCPU / 6 GB / 80 GB NVMe / 10 Gb/s — $19.99/мес Velocity — 8 vCPU / 12 GB / 160 GB NVMe / 10 Gb/s — $39.99/мес Overdrive — 12 vCPU / 24 GB / 320 GB NVMe / 10 Gb/s — $59.99/мес Выделенные серверы (Dedicated) — hstq.net/servers.html Xeon E-2186G / 32 GB / 480 GB SSD / 1 Gbit/s / NL — $99/мес Xeon E-2356G / 64 GB / 1 TB NVMe / 1 Gbit/s / SG — $119/мес 2× Xeon E5-2650v2 / 128 GB / 2×1 TB SSD / 10 Gbit/s / NL — $349/мес Xeon Gold 5218R / 128 GB / 2×1 TB NVMe / 10 Gbit/s / NL/US — $399/мес AMD EPYC 7702P / 128 GB / 2×2 TB NVMe / 25 Gbit/s / NL — $599/мес AMD EPYC 7702P / 128 GB / 2×2 TB NVMe / 40 Gbit/s / NL — $799/мес Аренда IPv4 (подсети): /27 (32 IP) — $49/мес /26 (64 IP) — $79/мес /25 (128 IP) — $99/мес /24 (256 IP) — $169/мес (LoA, WHOIS/PTR, анонс в другой ДЦ) /23 (512 IP) — $299/мес (LoA/WHOIS/PTR, анонс) /22 (1024 IP) — $499/мес (LoA/WHOIS/PTR, анонс) Администрирование (Linux): Эконом — $99/мес (4 ч/мес: обновления, базовая защита, бекапы, 24/7 мониторинг) Стандарт — $199/мес (12 ч/мес: +тюнинг, настройка ПО/фаервола, задачи/скрипты, 24/7 мониторинг) Премиум — $399/мес (30 ч/мес: +архитектура, HA, балансировка, DevOps, аудит безопасности, проактивный 24/7) Администрирование (Windows): Эконом — $199/мес (4 ч/мес, базовые работы и мониторинг) Стандарт — $299/мес (12 ч/мес, тюнинг IIS/ASP.NET, службы, триггеры мониторинга) Премиум — $499/мес (30 ч/мес, архитектура/HA, проактивный 24/7 SRE) Премиум (для любой ОС): шифрование дисков, администрирование хранилищ, геораспределённые сервисы, VPN/прокси. LIR / IP-ресурсы / ASN: Поддержка rDNS вашей сети (любой размер) — $50/мес (собственный DNS-парк) Помощь в получении /24 и регистрации LIR — $500 разово (членские взносы оплачиваются отдельно) Регистрация ASN — $399 разово Поддержка ASN — $199/год (взносы включены) PI /24 (покупка у нас) — $12 500 разово Бонус: при поддержке + регистрации ASN — IPv6 /32 бесплатно, пока активна поддержка ASN. Почему нам доверяют с первого заказа: — Быстрый старт: активация за минуты/часы и понятные SLA. — Прозрачные цены без скрытых условий + гарантия возврата 30 дней. — Поддержка, которая решает, а не «заводит тикет». — Оформление без KYC — быстрее и удобнее, но строго в рамках закона и AUP. Мы не требуем KYC при оформлении, потому что делаем услугу удобной и быстрой. Это не означает «серый» хостинг: мы соблюдаем законы юрисдикций, реагируем на abuse, поддерживаем best-practice (RPKI/IRR, фильтры) и не размещаем запрещённый контент. Наша задача — ускорить запуск, а не нарушать правила. Готовы начать сегодня? Выберите тариф ниже и опишите задачу — подберём конфигурацию, подготовим серверы и поможем с переносом. Если удобнее, напишите нам в Telegram: @hstq_hosting или в чат на сайте. Реквизиты и контакты: Юридическое лицо: BVI HSTQ Hosting quality service Reg. No.: 6949321 Registered Agent: Offshore Incorporations Limited Адрес: 18 Pasea Estate Road, Road Town, Tortola, VG1110, British Virgin Islands Телефон: +1 282-222-8282 E-mail: support@hstq.net, sales@hstq.net Telegram: @hstq_hosting, @hstq_official (новости) Тикет-система: cp.hstq.net → «Поддержка» → «Новый тикет» Сайт: hstq.net...
 Несколько дней назад мы обсуждали стратегию использования графических процессоров для ИИ в OVHcloud. После нескольких часов звонков я понял, что нашим финансовым коллегам всё ещё сложно разобраться в технических аспектах этой темы, поэтому я решил написать для них руководство. Потом кто-то пошутил, что многие наши клиенты тоже были в замешательстве, поэтому руководство теперь оформлено в виде поста в блоге. Это руководство посвящено графическому процессору для вывода больших языковых моделей (LLM). Под «производительностью» мы подразумеваем количество токенов в секунду. Это руководство не претендует на техническое погружение, но оно поможет вам выбрать правильную конфигурацию графического процессора для вашего сценария использования. Многие детали были упрощены для удобства и доступности информации. TL:DR – Лучшие варианты вывода LLM в OVHcloud (по состоянию на июль 2025) Это лучшие варианты развертывания, доступные на данный момент в OVHcloud для LLM-инференса. Предложение будет развиваться по мере выпуска новых графических процессоров.
Несколько дней назад мы обсуждали стратегию использования графических процессоров для ИИ в OVHcloud. После нескольких часов звонков я понял, что нашим финансовым коллегам всё ещё сложно разобраться в технических аспектах этой темы, поэтому я решил написать для них руководство. Потом кто-то пошутил, что многие наши клиенты тоже были в замешательстве, поэтому руководство теперь оформлено в виде поста в блоге. Это руководство посвящено графическому процессору для вывода больших языковых моделей (LLM). Под «производительностью» мы подразумеваем количество токенов в секунду. Это руководство не претендует на техническое погружение, но оно поможет вам выбрать правильную конфигурацию графического процессора для вашего сценария использования. Многие детали были упрощены для удобства и доступности информации. TL:DR – Лучшие варианты вывода LLM в OVHcloud (по состоянию на июль 2025) Это лучшие варианты развертывания, доступные на данный момент в OVHcloud для LLM-инференса. Предложение будет развиваться по мере выпуска новых графических процессоров.  1 — Определите область своих требований Прежде чем двигаться дальше, попробуйте определить свои требования (ответы на следующие вопросы помогут вам выбрать наилучшее решение). Какую модель вы хотите развернуть? (Например, Llama3 70B)Сколько у него параметров? (например, 7B, 70B, 120B)Какая длина контекста вам нужна? (например, 32 КБ, 128 КБ)Какой уровень точности или квантования? (FP16, FP8 и т. д.)Сколько пользователей одновременно? (Один пользователь? 10? 500? 10000 ?)Какой сервер вывода? (например, LLM, TensorRT, Ollama…)Необходимая пропускная способность? (например, задержка на пользователя, общее количество транзакций в секунду)Использование стабильное или нестабильное? Предсказуемое или нет? 2 – Выбор модели графического процессора – Дискриминантный критерий а) Поддержка квантования/точности Что такое квантование? Идея заключается в снижении точности весовых коэффициентов модели для уменьшения объёма памяти и вычислительных затрат ценой небольшого снижения качества модели. Квантование снижает затраты памяти и вычислительных затрат за счёт снижения точности (например, FP16 → FP8 → FP4), как правило, в ущерб качеству модели. Это компромисс. В настоящее время модели LLM чаще всего публикуются в FP16, но часто развертываются в FP8, поскольку выигрыш в скорости значительно перевешивает потерю качества. Поддержка квантования GPU
1 — Определите область своих требований Прежде чем двигаться дальше, попробуйте определить свои требования (ответы на следующие вопросы помогут вам выбрать наилучшее решение). Какую модель вы хотите развернуть? (Например, Llama3 70B)Сколько у него параметров? (например, 7B, 70B, 120B)Какая длина контекста вам нужна? (например, 32 КБ, 128 КБ)Какой уровень точности или квантования? (FP16, FP8 и т. д.)Сколько пользователей одновременно? (Один пользователь? 10? 500? 10000 ?)Какой сервер вывода? (например, LLM, TensorRT, Ollama…)Необходимая пропускная способность? (например, задержка на пользователя, общее количество транзакций в секунду)Использование стабильное или нестабильное? Предсказуемое или нет? 2 – Выбор модели графического процессора – Дискриминантный критерий а) Поддержка квантования/точности Что такое квантование? Идея заключается в снижении точности весовых коэффициентов модели для уменьшения объёма памяти и вычислительных затрат ценой небольшого снижения качества модели. Квантование снижает затраты памяти и вычислительных затрат за счёт снижения точности (например, FP16 → FP8 → FP4), как правило, в ущерб качеству модели. Это компромисс. В настоящее время модели LLM чаще всего публикуются в FP16, но часто развертываются в FP8, поскольку выигрыш в скорости значительно перевешивает потерю качества. Поддержка квантования GPU 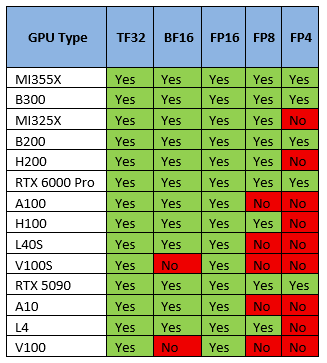 Большинство графических процессоров поддерживают не все типы точности/квантования, поэтому это дискриминантный критерий. Выберите графический процессор, поддерживающий нужный вам формат квантования. б) Минимальное количество графических процессоров для запуска вашей модели Для вывода необходимо загрузить все веса модели (**) в память (память видеокарты, а не ОЗУ) и оставить место для контекста/кэша. Либо памяти достаточно, либо это просто не сработает. Вот практическое правило расчета необходимого объема памяти GPU для LLM: Total GPU memory = (Parameters × Precision Factor) + (Context Size × 0.0005)
Большинство графических процессоров поддерживают не все типы точности/квантования, поэтому это дискриминантный критерий. Выберите графический процессор, поддерживающий нужный вам формат квантования. б) Минимальное количество графических процессоров для запуска вашей модели Для вывода необходимо загрузить все веса модели (**) в память (память видеокарты, а не ОЗУ) и оставить место для контекста/кэша. Либо памяти достаточно, либо это просто не сработает. Вот практическое правило расчета необходимого объема памяти GPU для LLM: Total GPU memory = (Parameters × Precision Factor) + (Context Size × 0.0005)  Пример: Llama 3.3 70B с контекстом 128 КБ в FP8 потребует 70 ГБ для весов модели + 62,5 ГБ для контекста. Если мы применим эту формулу к нескольким стандартным размерам/контекстам LLM, то получим следующее:
Пример: Llama 3.3 70B с контекстом 128 КБ в FP8 потребует 70 ГБ для весов модели + 62,5 ГБ для контекста. Если мы применим эту формулу к нескольким стандартным размерам/контекстам LLM, то получим следующее: 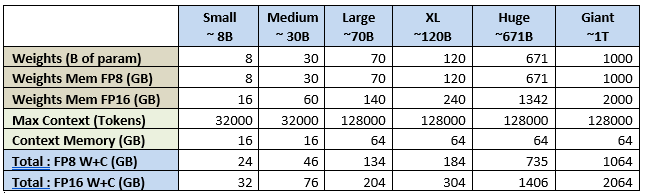 Теперь применим это к самому распространенному графическому процессору, который вы сможете найти, чтобы получить минимально необходимое вам количество графических процессоров:
Теперь применим это к самому распространенному графическому процессору, который вы сможете найти, чтобы получить минимально необходимое вам количество графических процессоров: 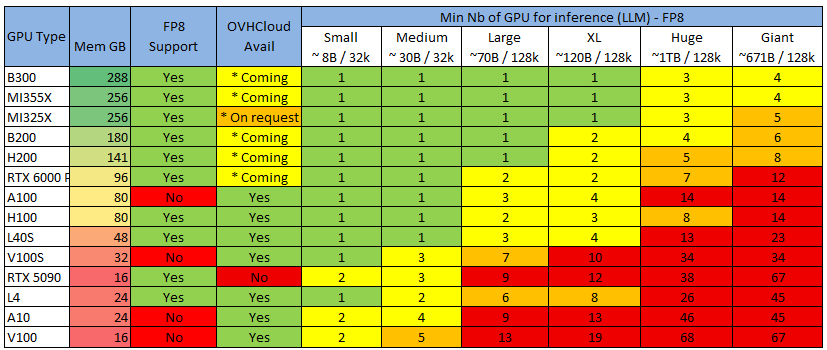
 Color Legend, учитывая, что серверы обычно поставляются с 4 или 8 GPU (скоро 16 GPU) См. также 2 распространенных метода точной настройки:
Color Legend, учитывая, что серверы обычно поставляются с 4 или 8 GPU (скоро 16 GPU) См. также 2 распространенных метода точной настройки: 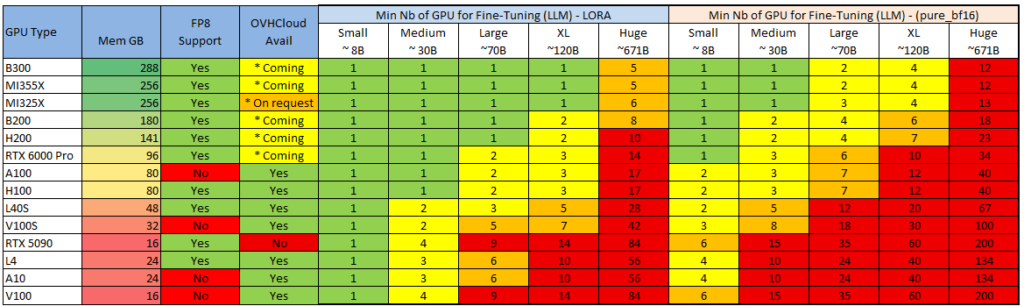 Примечание: возможно запустить (небольшой) вывод LLM на ЦП (см. Llama.cpp ), но только для небольших моделей (или высоких уровней квантования с более низким качеством). Примечание: можно сократить потребность в памяти, «выгрузив» часть слоев модели из ОЗУ, но я не буду об этом рассказывать (посмотрите Reddit-подписку LocalLlama — некоторые делают из этого вид спорта), так как производительность низкая, и я думаю, что если вы переходите в облако, то это ради реальных впечатлений c) Совместимость с оборудованием Последним критерием выбора графического процессора является аппаратная совместимость с некоторыми функциями серверов вывода. Серверы вывода (программное обеспечение, на котором работает модель) могут иметь функции, несовместимые с определенными графическими процессорами (марки или поколения). Они часто меняются, поэтому я не буду их перечислять, но вот пример для VLLM: docs.vllm.ai/en/latest/features/compatibility_matrix.html#feature-x-hardware_1 Самый распространенный пример, который мы видим, — это то, что механизм «Flash Attention» не поддерживается на видеокартах Nvidia поколения Tesla, таких как V100 и V100S 3 – Выбор конфигурации и развертывания графического процессора – Критерий производительности а) Что влияет на производительность вывода? Обзор На общую производительность (т. е. количество токенов в секунду) влияют несколько элементов, приблизительный порядок важности которых следующий: 1 – Производительность графического процессора2 – Производительность сети (между графическими процессорами и между серверами)3 – Программное обеспечение (сервер вывода, драйверы, ОС) Ниже приведено описание каждого из вариантов и варианты, которые можно выбрать. Производительность графического процессора В основном это связано с вычислительной мощностью («флопсами») графического процессора и пропускной способностью его памяти (в зависимости от поколения). Ознакомьтесь с теоретическими характеристиками (заявленными Nvidia и AMD), перечисленными ниже:
Примечание: возможно запустить (небольшой) вывод LLM на ЦП (см. Llama.cpp ), но только для небольших моделей (или высоких уровней квантования с более низким качеством). Примечание: можно сократить потребность в памяти, «выгрузив» часть слоев модели из ОЗУ, но я не буду об этом рассказывать (посмотрите Reddit-подписку LocalLlama — некоторые делают из этого вид спорта), так как производительность низкая, и я думаю, что если вы переходите в облако, то это ради реальных впечатлений c) Совместимость с оборудованием Последним критерием выбора графического процессора является аппаратная совместимость с некоторыми функциями серверов вывода. Серверы вывода (программное обеспечение, на котором работает модель) могут иметь функции, несовместимые с определенными графическими процессорами (марки или поколения). Они часто меняются, поэтому я не буду их перечислять, но вот пример для VLLM: docs.vllm.ai/en/latest/features/compatibility_matrix.html#feature-x-hardware_1 Самый распространенный пример, который мы видим, — это то, что механизм «Flash Attention» не поддерживается на видеокартах Nvidia поколения Tesla, таких как V100 и V100S 3 – Выбор конфигурации и развертывания графического процессора – Критерий производительности а) Что влияет на производительность вывода? Обзор На общую производительность (т. е. количество токенов в секунду) влияют несколько элементов, приблизительный порядок важности которых следующий: 1 – Производительность графического процессора2 – Производительность сети (между графическими процессорами и между серверами)3 – Программное обеспечение (сервер вывода, драйверы, ОС) Ниже приведено описание каждого из вариантов и варианты, которые можно выбрать. Производительность графического процессора В основном это связано с вычислительной мощностью («флопсами») графического процессора и пропускной способностью его памяти (в зависимости от поколения). Ознакомьтесь с теоретическими характеристиками (заявленными Nvidia и AMD), перечисленными ниже: 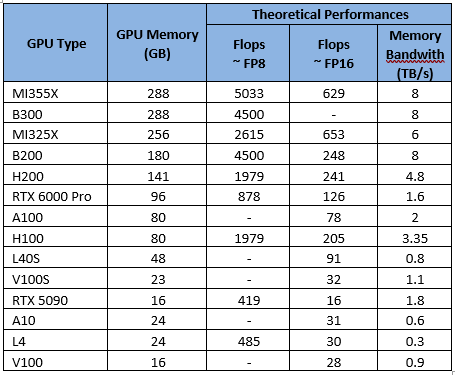 Производительность сети При выполнении вывода ваши данные распространяются несколькими способами: Видеокарта — материнская плата: скорость зависит от типа и версии подключения. Обычно это PCIE или SXM (фирменное подключение Nvidia).В двух словах: в целом SXM > PCIE, и чем выше версия, тем лучше. Видеокарта-видеокарта: связь осуществляется либо через материнскую плату (PCIE/SXM), либо через прямое соединение с видеокартой. Nvlink — это решение от Nvidia.В двух словах: если вы используете несколько графических процессоров Nvidia, выбирайте серверы с Nvlink. Сеть между серверами (при использовании нескольких серверов): Ethernet, InfinibandВ двух словах: если вы распределяете свои данные по нескольким серверам, выбирайте Infiniband по Ethernet. Производительность программного обеспечения (сервер вывода, драйверы) Производительность будет значительно варьироваться в зависимости от сервера вывода (VLLM, Ollama, TensorRT…), используемых базовых библиотек (Pytorch…) и базовых драйверов (Cuda, RocM). В двух словах: используйте последние версии! Не все серверы вывода обеспечивают одинаковую производительность и одинаковый набор функций. Я не буду вдаваться в подробности, но вот несколько советов: Ollama: Простота настройки и использования. Лучший вариант для одного пользователя.VLLM: Лучше всего подходит для быстрого получения последних моделей и функций, но сложно настроить.TensorRT: Лучшая пропускная способность, но есть задержка в поддержке новых моделей/функций и работает только на графических процессорах Nvidia. а) Различные варианты развертывания Теперь, когда вы знаете, какой графический процессор и сервер выбрать, у вас также есть несколько вариантов настройки архитектуры.
Производительность сети При выполнении вывода ваши данные распространяются несколькими способами: Видеокарта — материнская плата: скорость зависит от типа и версии подключения. Обычно это PCIE или SXM (фирменное подключение Nvidia).В двух словах: в целом SXM > PCIE, и чем выше версия, тем лучше. Видеокарта-видеокарта: связь осуществляется либо через материнскую плату (PCIE/SXM), либо через прямое соединение с видеокартой. Nvlink — это решение от Nvidia.В двух словах: если вы используете несколько графических процессоров Nvidia, выбирайте серверы с Nvlink. Сеть между серверами (при использовании нескольких серверов): Ethernet, InfinibandВ двух словах: если вы распределяете свои данные по нескольким серверам, выбирайте Infiniband по Ethernet. Производительность программного обеспечения (сервер вывода, драйверы) Производительность будет значительно варьироваться в зависимости от сервера вывода (VLLM, Ollama, TensorRT…), используемых базовых библиотек (Pytorch…) и базовых драйверов (Cuda, RocM). В двух словах: используйте последние версии! Не все серверы вывода обеспечивают одинаковую производительность и одинаковый набор функций. Я не буду вдаваться в подробности, но вот несколько советов: Ollama: Простота настройки и использования. Лучший вариант для одного пользователя.VLLM: Лучше всего подходит для быстрого получения последних моделей и функций, но сложно настроить.TensorRT: Лучшая пропускная способность, но есть задержка в поддержке новых моделей/функций и работает только на графических процессорах Nvidia. а) Различные варианты развертывания Теперь, когда вы знаете, какой графический процессор и сервер выбрать, у вас также есть несколько вариантов настройки архитектуры. 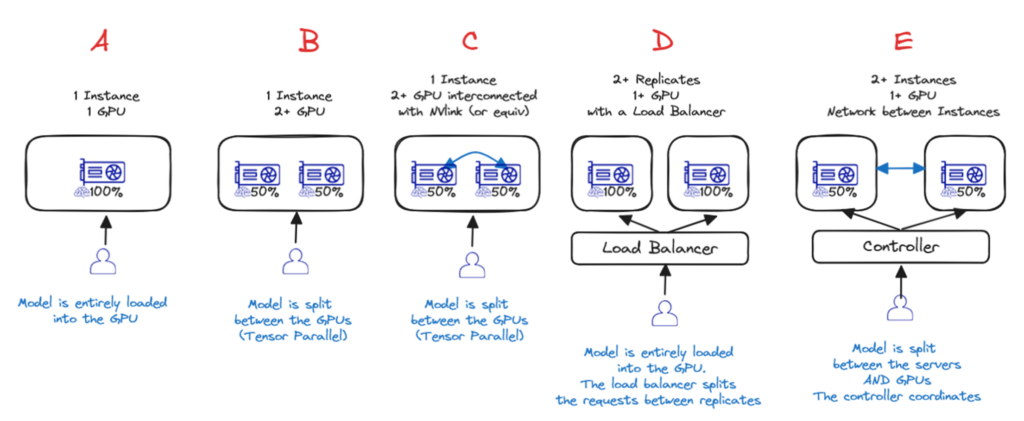 Вариант A — Один графический процессор Если модель достаточно мала, чтобы поместиться в один графический процессор, то это лучший вариант! Вариант B и C — один экземпляр, несколько графических процессоров (с межсоединени ем или без него) Если для одного GPU это слишком много, то лучшим вариантом будет один сервер с несколькими GPU. Либо с Nvlink ( вариант C ), либо без него ( вариант B ). В этих двух случаях веса моделей распределяются по разным GPU, но за это приходится платить: производительность не будет в два раза выше, чем у одного GPU! Вариант D — один экземпляр, несколько реплик с балансировкой нагрузки Если модель помещается на 1 сервере (1+ GPU), но производительности недостаточно или вам необходимо динамическое масштабирование в зависимости от текущих потребностей, то лучшим вариантом будет использование нескольких реплик и добавление балансировщика нагрузки ( вариант D ) — это то, что AI Deploy предоставляет по умолчанию. Вариант E — Распределенный вывод по нескольким серверам Если модель слишком велика для размещения на одном сервере, необходимо распределить вывод по нескольким серверам ( вариант E ). Это самый сложный вариант (необходимо настроить сеть и программное обеспечение для кластеризации) и приводит к наибольшей потере производительности (из-за узких мест в межсерверной сети, а также из-за взаимодействия графических процессоров). в) Какой продукт OVHcloud использовать? Для вывода у вас сегодня есть шесть вариантов на выбор:
Вариант A — Один графический процессор Если модель достаточно мала, чтобы поместиться в один графический процессор, то это лучший вариант! Вариант B и C — один экземпляр, несколько графических процессоров (с межсоединени ем или без него) Если для одного GPU это слишком много, то лучшим вариантом будет один сервер с несколькими GPU. Либо с Nvlink ( вариант C ), либо без него ( вариант B ). В этих двух случаях веса моделей распределяются по разным GPU, но за это приходится платить: производительность не будет в два раза выше, чем у одного GPU! Вариант D — один экземпляр, несколько реплик с балансировкой нагрузки Если модель помещается на 1 сервере (1+ GPU), но производительности недостаточно или вам необходимо динамическое масштабирование в зависимости от текущих потребностей, то лучшим вариантом будет использование нескольких реплик и добавление балансировщика нагрузки ( вариант D ) — это то, что AI Deploy предоставляет по умолчанию. Вариант E — Распределенный вывод по нескольким серверам Если модель слишком велика для размещения на одном сервере, необходимо распределить вывод по нескольким серверам ( вариант E ). Это самый сложный вариант (необходимо настроить сеть и программное обеспечение для кластеризации) и приводит к наибольшей потере производительности (из-за узких мест в межсерверной сети, а также из-за взаимодействия графических процессоров). в) Какой продукт OVHcloud использовать? Для вывода у вас сегодня есть шесть вариантов на выбор: 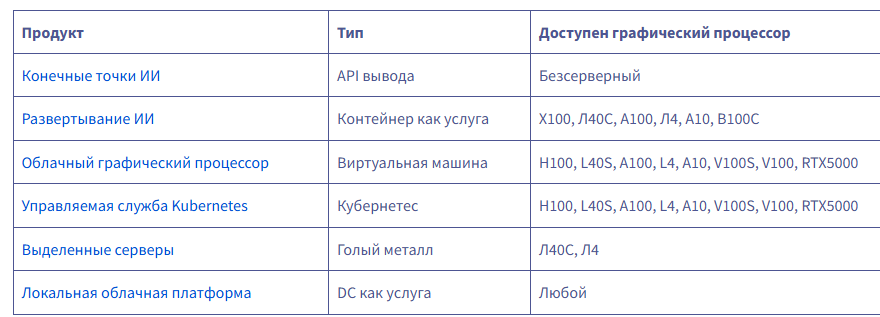 endpoints.ai.cloud.ovh.net/ www.ovhcloud.com/en/public-cloud/ai-deploy/ www.ovhcloud.com/en-ie/public-cloud/compute/ www.ovhcloud.com/en/public-cloud/kubernetes/ www.ovhcloud.com/en-ie/bare-metal/prices/ www.ovhcloud.com/en/dc-as-a-service/ Если вам нужен полностью управляемый вывод, то AI Endpoints — определённо лучший вариант: это бессерверный сервис, где вы платите за количество использованных токенов. Вам не нужно развертывать модель или управлять ею. Важно отметить, что вам нужно выбрать одну из предлагаемых нами моделей (вы не можете добавить свою). Тем не менее, мы приглашаем вас запрашивать новые модели на нашем Discord! discord.com/invite/ovhcloud AI Deploy — это продукт, специально разработанный для запуска серверов вывода, обладающий несколькими ключевыми функциями: Это контейнер как услуга: вы привозите свой собственный контейнер, мы им управляем.Простая конфигурация: вы можете запускать контейнер несколько раз с помощью одной командной строки и изменять параметры непосредственно через эту командную строку.Масштабируемость заложена в конструкцию: в любой момент вы можете добавить реплики, и мы управимся балансировкой нагрузки.Автомасштабирование: вы можете настроить автомасштабирование на основе пороговых значений ЦП/ОЗУ, а вскоре вы также сможете использовать пользовательские метрики (например, задержку вывода).Масштабирование до 0: Скоро вы сможете масштабироваться до 0. Если в течение некоторого времени на ваш сервер не отправляется ни одного запроса, мы останавливаем машину.Оплата поминутно, без обязательств...
endpoints.ai.cloud.ovh.net/ www.ovhcloud.com/en/public-cloud/ai-deploy/ www.ovhcloud.com/en-ie/public-cloud/compute/ www.ovhcloud.com/en/public-cloud/kubernetes/ www.ovhcloud.com/en-ie/bare-metal/prices/ www.ovhcloud.com/en/dc-as-a-service/ Если вам нужен полностью управляемый вывод, то AI Endpoints — определённо лучший вариант: это бессерверный сервис, где вы платите за количество использованных токенов. Вам не нужно развертывать модель или управлять ею. Важно отметить, что вам нужно выбрать одну из предлагаемых нами моделей (вы не можете добавить свою). Тем не менее, мы приглашаем вас запрашивать новые модели на нашем Discord! discord.com/invite/ovhcloud AI Deploy — это продукт, специально разработанный для запуска серверов вывода, обладающий несколькими ключевыми функциями: Это контейнер как услуга: вы привозите свой собственный контейнер, мы им управляем.Простая конфигурация: вы можете запускать контейнер несколько раз с помощью одной командной строки и изменять параметры непосредственно через эту командную строку.Масштабируемость заложена в конструкцию: в любой момент вы можете добавить реплики, и мы управимся балансировкой нагрузки.Автомасштабирование: вы можете настроить автомасштабирование на основе пороговых значений ЦП/ОЗУ, а вскоре вы также сможете использовать пользовательские метрики (например, задержку вывода).Масштабирование до 0: Скоро вы сможете масштабироваться до 0. Если в течение некоторого времени на ваш сервер не отправляется ни одного запроса, мы останавливаем машину.Оплата поминутно, без обязательств...
 С 6.10.2025 в инфраструктуре Selectel вступят в силу следующие изменения, направленные на повышение уровня безопасности объектного S3 хранилища: FTP (регион ru-1): Включается обязательное использование защищённого протокола FTPS. SFTP: Прекращается поддержка устаревших методов шифрования SSH: 3des-cbcaes128-cbcaes192-cbcaes256-cbcblowfish-cbc Прекращается поддержка устаревшего алгоритма обмена ключами: diffie-hellman-group1-sha1 Общие изменения: Минимальная поддерживаемая версия TLS повышается до v1.2. Эти меры позволят обеспечить соответствие современным требованиям безопасности и лучшую защиту ваших данных. Если у вас есть вопросы или потребуется помощь в адаптации настроек подключения — наша команда поддержки готова помочь...
С 6.10.2025 в инфраструктуре Selectel вступят в силу следующие изменения, направленные на повышение уровня безопасности объектного S3 хранилища: FTP (регион ru-1): Включается обязательное использование защищённого протокола FTPS. SFTP: Прекращается поддержка устаревших методов шифрования SSH: 3des-cbcaes128-cbcaes192-cbcaes256-cbcblowfish-cbc Прекращается поддержка устаревшего алгоритма обмена ключами: diffie-hellman-group1-sha1 Общие изменения: Минимальная поддерживаемая версия TLS повышается до v1.2. Эти меры позволят обеспечить соответствие современным требованиям безопасности и лучшую защиту ваших данных. Если у вас есть вопросы или потребуется помощь в адаптации настроек подключения — наша команда поддержки готова помочь...
Cloud4Y наращивает мощь: в Подмосковье строим два современных ЦОД — в Мытищах и Марфино. Это по 2400 серверных стоек, размещаемых в капитальных зданиях и в контейнерах. Оба объекта станут частью единой высокодоступной экосистемы — для вашего масштабирования и надёжности. Марфино: закладываем фундамент мощности и надёжности Июль был месяцем электричества, а в августе мы комплексно проработали вопрос всей инженерной инфраструктуры будущего ЦОД. Одновременно занимались несколькими критически важным направлениям. Марфино — Заложили основу для энергомощности в 24 МВт и усилили инженерную инфраструктуру.Мытищи — Завершили важный этап подготовительных работ. 1. Энергия будущего: газ для бесперебойной работы Активно работаем с «Мособлгазом» — нам важно согласовать проект газоснабжения. Это ответственный этап. Газоснабжение — ключ к эффективному электроснабжению нашего объекта. Оно обеспечит работу газопоршневых электростанций, которые в перспективе позволят запитать участок электроэнергией до 24 МВт. 2. Газопоршневые генераторные установки: готовимся к приёмке Ожидаем поставки нескольких газопоршневых генераторных установок (ГПУ) мощностью по 1 МВт каждая. Уже сейчас готовим и расчищаем площадку для их последующего монтажа. Будем интегрировать ГПУ в общую систему энергоснабжения. Надёжность — это всегда многоуровневая система.  3. Дизельные генераторы: запланировали приёмку Параллельно мы готовим резервные источники питания. На площадку доставят несколько дизельных генераторов мощностью по 1,52 МВт каждый. Нам важно обеспечить резерв в газовой генерации.
3. Дизельные генераторы: запланировали приёмку Параллельно мы готовим резервные источники питания. На площадку доставят несколько дизельных генераторов мощностью по 1,52 МВт каждый. Нам важно обеспечить резерв в газовой генерации.  4. Проектирование и оборудование: всё по плану Продолжаются проектные работы по самому дата-центру. Мы пристально изучаем и выбираем ключевое оборудование для инженерных систем будущего ЦОД. Это сложный и кропотливый процесс, от которого зависит будущая эффективность и отказоустойчивость. 5. Электричество и коммуникации: наращиваем темпы Силовые линии Продолжаем прокладку силовых кабельных линий и готовимся к подключению дополнительных мощностей. Так мы создаём основу энергоснабжения будущего ЦОД, от которой зависит работа каждого сервера. Водоотведение Заключили договор и начали работы по присоединению к центральным сетям водоотведения. Эта система критически важна для работы комплекса в целом. Связь Получили согласование от операторов на создание прямого канала связи с М9 — центральным узлом обмена трафиком в России. Это гарантирует нам в будущем высочайшую скорость и стабильность подключения к крупным узлам связи. Мытищи: этап подготовительных работ завершён Завершается комплекс изысканий по земельному участку и инженерным коммуникациям, а также экспертиз существующих строений для использования в составе ЦОД. Теперь у нас на руках есть полный пакет документов и точное понимание состояния площадки. Это абсолютно необходимая основа для того, чтобы принять финальные проектные решения и начать активные строительные работы. В фокусе — ваша стабильность Каждый согласованный документ, каждый проложенный метр кабеля и каждая выбранная установка — это кирпичик в фундаменте вашего спокойствия. Наши собственные ЦОД — это залог предсказуемой производительности, безопасности данных и независимости для вашего бизнеса. Почему именно Марфино и Мытищи? Нас часто спрашивают в комментариях о выборе локаций для наших дата-центров. Отвечаем! Решение строить за пределами Москвы, в Подмосковье, — это стратегический выбор. В итоге наши клиенты ощутят выгоду: Экономическая обоснованность Процедуры согласований проходят проще и быстрее, чем в столице. Вдобавок тарифы там более выгодные. Это касается и этапа строительства — CAPEX, и эксплуатации — OPEX. Так мы создаём конкурентоспособный продукт без компромиссов в качестве. Безопасность и отказоустойчивость Объекты в менее населённой зоне меньше подвержены различным рискам — от промышленных и транспортных до социальных. Так мы повышаем общую надёжность инфраструктуры. Идеальный баланс При этом незначительная удалённость от Москвы не создаёт проблем с логистикой, но технологически обеспечивает корректную работу резервной площадки при построении распределённой инфраструктуры. А почему именно север? Здесь тоже есть чёткая логика: Развитие рынка На севере Подмосковья сегодня незначительное количество качественных ЦОДов, и мы закрываем эту потребность. Сетевая география Строительные площадки расположены в 80 км от центрального узла обмена трафиком М9. Такое расстояние обеспечивает идеальную разнесённость для того, чтобы выстроить высокоскоростные каналы связи между ЦОДами. В итоге получим надёжное кольцо. И не нужно дополнительно устанавливать дорогостоящее сетевое оборудование для усиления сигнала. Решение опять же положительно сказывается на итоговой стоимости услуг. www.cloud4y.ru...
4. Проектирование и оборудование: всё по плану Продолжаются проектные работы по самому дата-центру. Мы пристально изучаем и выбираем ключевое оборудование для инженерных систем будущего ЦОД. Это сложный и кропотливый процесс, от которого зависит будущая эффективность и отказоустойчивость. 5. Электричество и коммуникации: наращиваем темпы Силовые линии Продолжаем прокладку силовых кабельных линий и готовимся к подключению дополнительных мощностей. Так мы создаём основу энергоснабжения будущего ЦОД, от которой зависит работа каждого сервера. Водоотведение Заключили договор и начали работы по присоединению к центральным сетям водоотведения. Эта система критически важна для работы комплекса в целом. Связь Получили согласование от операторов на создание прямого канала связи с М9 — центральным узлом обмена трафиком в России. Это гарантирует нам в будущем высочайшую скорость и стабильность подключения к крупным узлам связи. Мытищи: этап подготовительных работ завершён Завершается комплекс изысканий по земельному участку и инженерным коммуникациям, а также экспертиз существующих строений для использования в составе ЦОД. Теперь у нас на руках есть полный пакет документов и точное понимание состояния площадки. Это абсолютно необходимая основа для того, чтобы принять финальные проектные решения и начать активные строительные работы. В фокусе — ваша стабильность Каждый согласованный документ, каждый проложенный метр кабеля и каждая выбранная установка — это кирпичик в фундаменте вашего спокойствия. Наши собственные ЦОД — это залог предсказуемой производительности, безопасности данных и независимости для вашего бизнеса. Почему именно Марфино и Мытищи? Нас часто спрашивают в комментариях о выборе локаций для наших дата-центров. Отвечаем! Решение строить за пределами Москвы, в Подмосковье, — это стратегический выбор. В итоге наши клиенты ощутят выгоду: Экономическая обоснованность Процедуры согласований проходят проще и быстрее, чем в столице. Вдобавок тарифы там более выгодные. Это касается и этапа строительства — CAPEX, и эксплуатации — OPEX. Так мы создаём конкурентоспособный продукт без компромиссов в качестве. Безопасность и отказоустойчивость Объекты в менее населённой зоне меньше подвержены различным рискам — от промышленных и транспортных до социальных. Так мы повышаем общую надёжность инфраструктуры. Идеальный баланс При этом незначительная удалённость от Москвы не создаёт проблем с логистикой, но технологически обеспечивает корректную работу резервной площадки при построении распределённой инфраструктуры. А почему именно север? Здесь тоже есть чёткая логика: Развитие рынка На севере Подмосковья сегодня незначительное количество качественных ЦОДов, и мы закрываем эту потребность. Сетевая география Строительные площадки расположены в 80 км от центрального узла обмена трафиком М9. Такое расстояние обеспечивает идеальную разнесённость для того, чтобы выстроить высокоскоростные каналы связи между ЦОДами. В итоге получим надёжное кольцо. И не нужно дополнительно устанавливать дорогостоящее сетевое оборудование для усиления сигнала. Решение опять же положительно сказывается на итоговой стоимости услуг. www.cloud4y.ru...
 SHAI — это передовой ИИ-помощник для терминала, призванный упростить ваши повседневные задачи по разработке. Создаёте ли вы веб-сайт, редактируете файлы, запускаете команды оболочки или автоматизируете сложные рабочие процессы, Shai поможет вам — и всё это прямо с вашего терминала. labs.ovhcloud.com/en/shai/...
SHAI — это передовой ИИ-помощник для терминала, призванный упростить ваши повседневные задачи по разработке. Создаёте ли вы веб-сайт, редактируете файлы, запускаете команды оболочки или автоматизируете сложные рабочие процессы, Shai поможет вам — и всё это прямо с вашего терминала. labs.ovhcloud.com/en/shai/...
 Давайте вместе позаботимся о природе Раз в год команда Selectel выезжает в лес высаживать деревья. Так мы вносим вклад в развитие регионов, где находятся наши дата-центры. Проект называется «Зеленый Selectel» и проходит уже шестой раз подряд. За это время мы высадили более 120 000 саженцев. Продолжим традицию и в 2025 году. Присоединяйтесь! promo.selectel.ru/greenselectel2025
Давайте вместе позаботимся о природе Раз в год команда Selectel выезжает в лес высаживать деревья. Так мы вносим вклад в развитие регионов, где находятся наши дата-центры. Проект называется «Зеленый Selectel» и проходит уже шестой раз подряд. За это время мы высадили более 120 000 саженцев. Продолжим традицию и в 2025 году. Присоединяйтесь! promo.selectel.ru/greenselectel2025  ...
...
 Если ваш проект работает с высокими нагрузками — от 1С‑Битрикс до интенсивного парсинга или требовательного ПО, где каждая миллисекунда критична, ключевое значение приобретает скорость CPU. Для таких задач мы предлагаем выделенные серверы на базе мощных высокочастотных процессоров:
Если ваш проект работает с высокими нагрузками — от 1С‑Битрикс до интенсивного парсинга или требовательного ПО, где каждая миллисекунда критична, ключевое значение приобретает скорость CPU. Для таких задач мы предлагаем выделенные серверы на базе мощных высокочастотных процессоров: 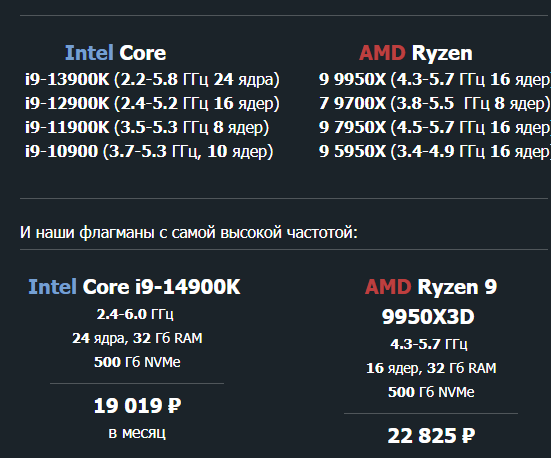 Платформы с высокочастотными CPU поддерживают: до 256 Гб RAM,до 2 накопителей NVMe объемом до 8 000 Гб каждый,до 4 дисков SSD до 7680 Гб и (или) HDD до 24000 Гб. Также большая часть таких процессоров оборудована водяным охлаждением для непрерывной и стабильной работы. 1dedic.ru...
Платформы с высокочастотными CPU поддерживают: до 256 Гб RAM,до 2 накопителей NVMe объемом до 8 000 Гб каждый,до 4 дисков SSD до 7680 Гб и (или) HDD до 24000 Гб. Также большая часть таких процессоров оборудована водяным охлаждением для непрерывной и стабильной работы. 1dedic.ru...

 Добрый день, H3llo! Мы тут готовимся к публичному запуску последнего коммерческого облака в России и не хотим стрелять себе в ногу. А самый проверенный способ выстрелить себе в ногу — стать корпоратами, деплоить в пятницу вечером, отключить файрвол на минуточку для теста и не слушать сообщество. Поэтому я пришёл к вам с вопросами. Их всего три: что у вас случалось раньше плохого с облаками или хостингами, что бы вы хотели исправить и что вы бы лично хотели от нашего облака. Ответить можно тут. Займёт от 30 секунд до 1 года, но медиана где-то в районе 3 минут. survey.h3llo.cloud
Добрый день, H3llo! Мы тут готовимся к публичному запуску последнего коммерческого облака в России и не хотим стрелять себе в ногу. А самый проверенный способ выстрелить себе в ногу — стать корпоратами, деплоить в пятницу вечером, отключить файрвол на минуточку для теста и не слушать сообщество. Поэтому я пришёл к вам с вопросами. Их всего три: что у вас случалось раньше плохого с облаками или хостингами, что бы вы хотели исправить и что вы бы лично хотели от нашего облака. Ответить можно тут. Займёт от 30 секунд до 1 года, но медиана где-то в районе 3 минут. survey.h3llo.cloud  Заранее большое спасибо! Не обещаю, что всё это имплементируем, но обещаю, что очень внимательно к этому отнесёмся и потом поделимся с вами и сообществом результатами всего опроса. Мне серьёзно очень важно услышать про ваш опыт, потому что мы делаем облако без херни. По крайней мере, стараемся. С уважением, Константин \m/ H3LLO.CLOUD h3llo.cloud/ru/...
Заранее большое спасибо! Не обещаю, что всё это имплементируем, но обещаю, что очень внимательно к этому отнесёмся и потом поделимся с вами и сообществом результатами всего опроса. Мне серьёзно очень важно услышать про ваш опыт, потому что мы делаем облако без херни. По крайней мере, стараемся. С уважением, Константин \m/ H3LLO.CLOUD h3llo.cloud/ru/...
У нас в названии есть слово «гиперскейлер». На подкасте меня спросили, а что это. Я прям растерялся. Это хостинг масштабом больше любого потенциального клиента в разы. В смысле, когда у клиента случится пиковая нагрузка, он сможет получить все нужные ресурсы. Это значит несколько неочевидных вещей: Нет единого крупного клиента (привет, Сбер).График потребления ресурсов у клиентов разный (а не облако для розницы, падающее в чёрную пятницу).Есть свободные ресурсы или ресурсы, с которых можно сдвинуть какие-то проекты вроде месячного расчёта для поиска обитаемых планет в фоновом режиме.Есть платформа, которая позволяет так масштабироваться.Есть куча автоматизаций, которые решают проблемы свёртывания-развёртывания.Напомню, мы выкинули всё, что раньше делали другие (потому что у других получился Опенстек), переосмыслили всё это полностью и написали свою платформу. У нас никакого легаси, сложных совместимостей, зато есть самое топовое железо. И как следствие мы строим лучший пользовательский опыт. Мы не идём в сторону сотен сервисов, как у Амазона. Мы идём в сторону того, чтобы это было просто, понятно, удобно и экономически эффективно. Местами получается. Мы только начали. h3llo.cloud/ru/...
 promo.selectel.ru/rauitevent
promo.selectel.ru/rauitevent  ...
...
Немецкий сервис-провайдер CloudKleyer предлагает бизнесу в аренду полные серверные стойки с увеличенной мощностью питания до 60 kW. Такое решение позволяет консолидировать высокопроизводительные аппаратные ресурсы и хорошо подходит компаниям, работающим с технологиями искусственного интеллекта и машинного обучения. CloudKleyer оказывает услугу в дата-центре класса Tier 3 во Франкфурте-на-Майне – интернет-столице Европы. Условия подключения полностью соответствуют высочайшим стандартам и требованиям безопасности. Благодаря специализированным hardware solutions мощность питания для серверной стойки вместо стандартных 8 kW можно увеличить до 20 kW, 30 kW или даже 60 kW. Благодаря выгодному географическому расположению центра обработки данных клиенты CloudKleyer получают возможность использовать не только самые передовые аппаратные решения, но и пользоваться выделенными высокоскоростными интернет-каналами с пропускной способностью до 10 Gbps, напрямую подключать свою IT-инфраструктуру к крупным облачным платформам, таким как AWS, Azure и Google Cloud. В условиях, когда более 90% площадей в крупных европейских дата-центрах уже занято, CloudKleyer может предложить лучшие условия на услуги Colocation. Бесплатный интернет со скоростью до 100 Mbps для каждого клиентаАренда полной стойки, половины стойки и любого количества rack spaceCage colocation для критически важного оборудованияПолный комплекс услуг по техническому обслуживанию Remote HandsПеред заключением соглашения можно получить полную информацию о стандартах и технологиях безопасности и даже заказать тур по дата-центру. CloudKleyer Frankfurt GmbH – сервис-провайдер с 10-летней историей успеха. Основные преимущества компании – отзывчивость и предоставление сервиса неизменно высокого качества во всех точках присутствия. Связаться с представителями CloudKleyer вы можете, отправив сообщение на contact@cloudkleyer.de либо по номеру телефона в Германии +49 696 61696780...
 До Дня Программиста ещё целая неделя, но мы решили сделать вам приятный сюрприз заранее Теперь наши клиенты могут воспользоваться обновлёнными тарифами «Старт++» с большим объёмом оперативной памяти абсолютно бесплатно! Стоимость ваших текущих тарифов остаётся прежней, а возможности растут вместе с вами. Хотите больше ресурсов для своего проекта? Переходите на новый тариф прямо сейчас одним из двух простых способов: ✅ Через личный кабинет в биллинге ✅ Отправив заявку через тикет P.S.: Ещё одно важное дополнение: Наши старые тарифы «Старт+» теперь будут перенесены в архив. Это значит, что вы сможете продолжать работу и продление услуг на старых условиях, однако новые заказы по тарифам «Старт» и «Старт+» оформить уже не получится. Если хотите расширить свои возможности, переходите на «Старт++» уже сейчас! ✨ Тарифы ПромоSSD+ и Старт0+ эти изменения не затронули, они также доступны, но без изменений по размеру памяти.
До Дня Программиста ещё целая неделя, но мы решили сделать вам приятный сюрприз заранее Теперь наши клиенты могут воспользоваться обновлёнными тарифами «Старт++» с большим объёмом оперативной памяти абсолютно бесплатно! Стоимость ваших текущих тарифов остаётся прежней, а возможности растут вместе с вами. Хотите больше ресурсов для своего проекта? Переходите на новый тариф прямо сейчас одним из двух простых способов: ✅ Через личный кабинет в биллинге ✅ Отправив заявку через тикет P.S.: Ещё одно важное дополнение: Наши старые тарифы «Старт+» теперь будут перенесены в архив. Это значит, что вы сможете продолжать работу и продление услуг на старых условиях, однако новые заказы по тарифам «Старт» и «Старт+» оформить уже не получится. Если хотите расширить свои возможности, переходите на «Старт++» уже сейчас! ✨ Тарифы ПромоSSD+ и Старт0+ эти изменения не затронули, они также доступны, но без изменений по размеру памяти. 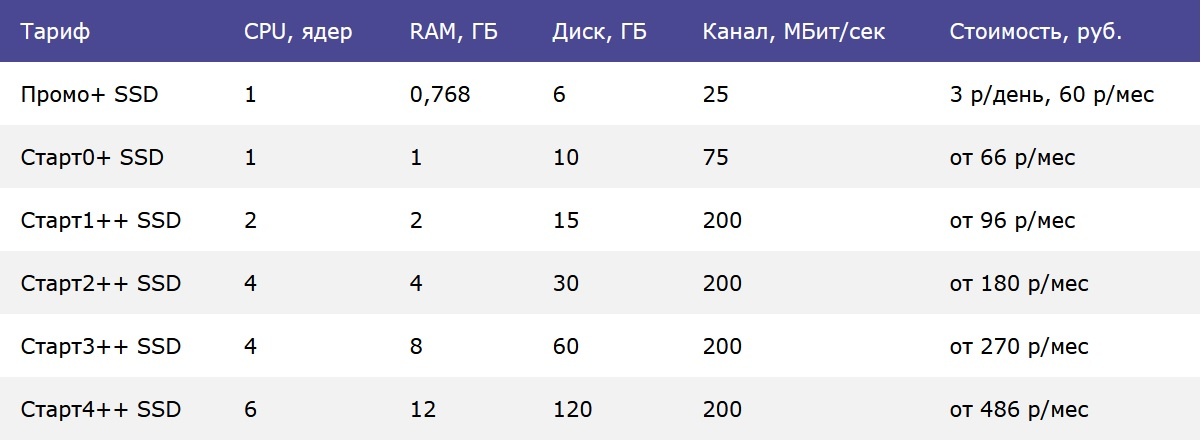 elenahost.ru...
elenahost.ru...