Уважаемый клиент, сегодня в 00:29 (МСК) мы зафиксировали интенсивную DDoS-атаку на наши IP-адреса в локациях AMS1 и AMS3 (Амстердам, Нидерланды) и в облачных регионах Амстердам — зона 1-4. Атака повлияла на работу публичной сети в регионе. Во время атаки вы могли наблюдать увеличение задержек и потерю пакетов по публичной сети вплоть до 100%. Мы устранили влияние атаки, и сейчас публичная сеть работает в штатном режиме. Детали: Время начала первой атаки: 6 сентября 2025, 00:29 (МСК) Время восстановления работы сети: 6 сентября 2025, 00:30 (МСК) Время начала второй атаки: 6 сентября 2025, 00:50 (МСК) Время восстановления работы сети: 6 сентября 2025, 00:52 (МСК) Время начала третьей атаки: 6 сентября 2025, 01:03 (МСК) Время восстановления работы сети: 6 сентября 2025, 01:13 (МСК) Общий период ограничений: 13 минут Облачное хранилище в регионе Амстердам Приносим свои извинения за доставленные неудобства. С уважением, команда поддержки Servers.ru...
Мы пишем вам, чтобы сообщить о предстоящем изменении цен на домены на Resell.biz. В Resell.biz мы всегда стремились предлагать вам самые конкурентоспособные цены на домены на рынке. Годами мы упорно трудились, чтобы оставаться выгодным выбором как для реселлеров доменов, так и для прямых покупателей. Однако в связи с недавними изменениями на рынке и ростом эксплуатационных расходов мы скорректируем цены для наших клиентов и реселлеров. С 4 октября 2025 года цены на регистрацию, продление, передачу и восстановление наших доменов вырастут, что затронет реселлеров и прямых клиентов. Реселлеры смогут ознакомиться с новыми ценами на нашем платежном портале 4 октября. Мы ценим ваше понимание и неизменное доверие к Resell.biz как к партнеру по реселлингу доменов. Если у вас есть вопросы или вам требуются дополнительные разъяснения, пожалуйста, свяжитесь с нами по адресу support@resell.biz или посетите нашу страницу поддержки. Благодарим вас за сотрудничество и за то, что вы растете вместе с нами. С наилучшими пожеланиями, Команда Resell.biz...
 Начиная работу над проектом, вы ожидаете, что он будет выполняться без сбоев. Это ожидание справедливо во многих областях, но особенно остро оно ощущается инженерами машинного обучения, которые запускают масштабные проекты по предобучению. Поддержание стабильной среды обучения критически важно для достижения результатов в области ИИ в срок и в рамках бюджета. За последние несколько месяцев в Nebius мы добились значительного прогресса в повышении надежности кластера, обеспечив отказоустойчивое обучение для всех наших клиентов. Эти улучшения привели к 169 800 часов работы графических процессоров или 56,6 часов стабильной работы для производственного кластера из 3000 графических процессоров, как записал один из наших клиентов. Подписи, ведущая компания в области видеонаблюдения на основе ИИ, подчеркивает стабильность кластеров Nebius и показывает, насколько они важны для прогресса в разработке ИИ. Благодаря Nebius наши долгосрочные задачи по обучению стали более предсказуемыми и эффективными. Повышение автоматизации обработки неисправностей и низкий уровень инцидентов позволили нам уделять больше времени отработке новых моделей, а не управлению инфраструктуройГаурав Мисра, соучредитель и генеральный директор Captions В этой статье мы расскажем вам об основных концепциях и показателях, определяющих надежность кластеров ИИ, а также расскажем о методах, которые используют инженеры Nebius для обучения наших клиентов отказоустойчивости. Проблема запуска учебных заданий на многоузловом кластере Распределённое обучение ИИ подразумевает запуск модели на нескольких узлах, каждый из которых обрабатывает часть рабочей нагрузки и синхронизируется с остальными. Это ускоряет обучение, но и делает его более уязвимым. Если один узел выйдет из строя, это может прервать всю работу, сбрасывая ход обучения до последней контрольной точки и тратя драгоценное вычислительное время. В кластере из 1024 графических процессоров это означает, что 1023 исправных графических процессора будут простаивать, пока неисправный узел восстанавливается или заменяется. С увеличением размера кластера пропорционально растёт риск сбоя. Каждый дополнительный узел усложняет аппаратное и программное обеспечение, что увеличивает вероятность возникновения сбоев. Пересмотр надежности в крупномасштабных исследовательских кластерах машинного обучения В статье этот факт наглядно проиллюстрирован. Метрика среднего времени до отказа (MTTF) для кластеров разных масштабов представлена ниже: На 1024 GPU время до полной готовности (MTTF) составляет 7,9 часов.На 16 384 графических процессорах среднее время до отказа составляет 1,8 часа.На 131 072 графических процессорах среднее время до полной готовности (MTTF) составляет 14 минут. Причины перерывов в работе во время масштабного обучения Как мы видим, перерывы в работе неизбежны. Более того, они ожидаемы в крупных учебных кластерах и могут возникнуть по следующим причинам: Плановые события (обслуживание кластера или перезапуски, инициированные пользователем)Незапланированные сбои инфраструктуры (оборудования, сетей, хранилищ)Проблемы со стороны пользователя (ошибки обучающего кода, неправильные конфигурации)Исследовательская работа Метыобнаружили, что для 54-дневного задания по обучению на кластере из 16 000 графических процессоров около 78% непредвиденных прерываний задания были связаны с проблемами оборудования, тогда как на ошибки программного обеспечения пришлось всего лишь около 12,9% прерываний.Наиболее распространенные отказы оборудования возникают из-запроблемы с внутренней сетью, проблемы с файловой системой и сбои в работе графического процессора, подчеркивая, что сбои на уровне инфраструктуры являются основной причиной прерывания учебного процесса. Кроме того, именно эти компоненты наименее заметны и контролируемы пользователями.
Начиная работу над проектом, вы ожидаете, что он будет выполняться без сбоев. Это ожидание справедливо во многих областях, но особенно остро оно ощущается инженерами машинного обучения, которые запускают масштабные проекты по предобучению. Поддержание стабильной среды обучения критически важно для достижения результатов в области ИИ в срок и в рамках бюджета. За последние несколько месяцев в Nebius мы добились значительного прогресса в повышении надежности кластера, обеспечив отказоустойчивое обучение для всех наших клиентов. Эти улучшения привели к 169 800 часов работы графических процессоров или 56,6 часов стабильной работы для производственного кластера из 3000 графических процессоров, как записал один из наших клиентов. Подписи, ведущая компания в области видеонаблюдения на основе ИИ, подчеркивает стабильность кластеров Nebius и показывает, насколько они важны для прогресса в разработке ИИ. Благодаря Nebius наши долгосрочные задачи по обучению стали более предсказуемыми и эффективными. Повышение автоматизации обработки неисправностей и низкий уровень инцидентов позволили нам уделять больше времени отработке новых моделей, а не управлению инфраструктуройГаурав Мисра, соучредитель и генеральный директор Captions В этой статье мы расскажем вам об основных концепциях и показателях, определяющих надежность кластеров ИИ, а также расскажем о методах, которые используют инженеры Nebius для обучения наших клиентов отказоустойчивости. Проблема запуска учебных заданий на многоузловом кластере Распределённое обучение ИИ подразумевает запуск модели на нескольких узлах, каждый из которых обрабатывает часть рабочей нагрузки и синхронизируется с остальными. Это ускоряет обучение, но и делает его более уязвимым. Если один узел выйдет из строя, это может прервать всю работу, сбрасывая ход обучения до последней контрольной точки и тратя драгоценное вычислительное время. В кластере из 1024 графических процессоров это означает, что 1023 исправных графических процессора будут простаивать, пока неисправный узел восстанавливается или заменяется. С увеличением размера кластера пропорционально растёт риск сбоя. Каждый дополнительный узел усложняет аппаратное и программное обеспечение, что увеличивает вероятность возникновения сбоев. Пересмотр надежности в крупномасштабных исследовательских кластерах машинного обучения В статье этот факт наглядно проиллюстрирован. Метрика среднего времени до отказа (MTTF) для кластеров разных масштабов представлена ниже: На 1024 GPU время до полной готовности (MTTF) составляет 7,9 часов.На 16 384 графических процессорах среднее время до отказа составляет 1,8 часа.На 131 072 графических процессорах среднее время до полной готовности (MTTF) составляет 14 минут. Причины перерывов в работе во время масштабного обучения Как мы видим, перерывы в работе неизбежны. Более того, они ожидаемы в крупных учебных кластерах и могут возникнуть по следующим причинам: Плановые события (обслуживание кластера или перезапуски, инициированные пользователем)Незапланированные сбои инфраструктуры (оборудования, сетей, хранилищ)Проблемы со стороны пользователя (ошибки обучающего кода, неправильные конфигурации)Исследовательская работа Метыобнаружили, что для 54-дневного задания по обучению на кластере из 16 000 графических процессоров около 78% непредвиденных прерываний задания были связаны с проблемами оборудования, тогда как на ошибки программного обеспечения пришлось всего лишь около 12,9% прерываний.Наиболее распространенные отказы оборудования возникают из-запроблемы с внутренней сетью, проблемы с файловой системой и сбои в работе графического процессора, подчеркивая, что сбои на уровне инфраструктуры являются основной причиной прерывания учебного процесса. Кроме того, именно эти компоненты наименее заметны и контролируемы пользователями. 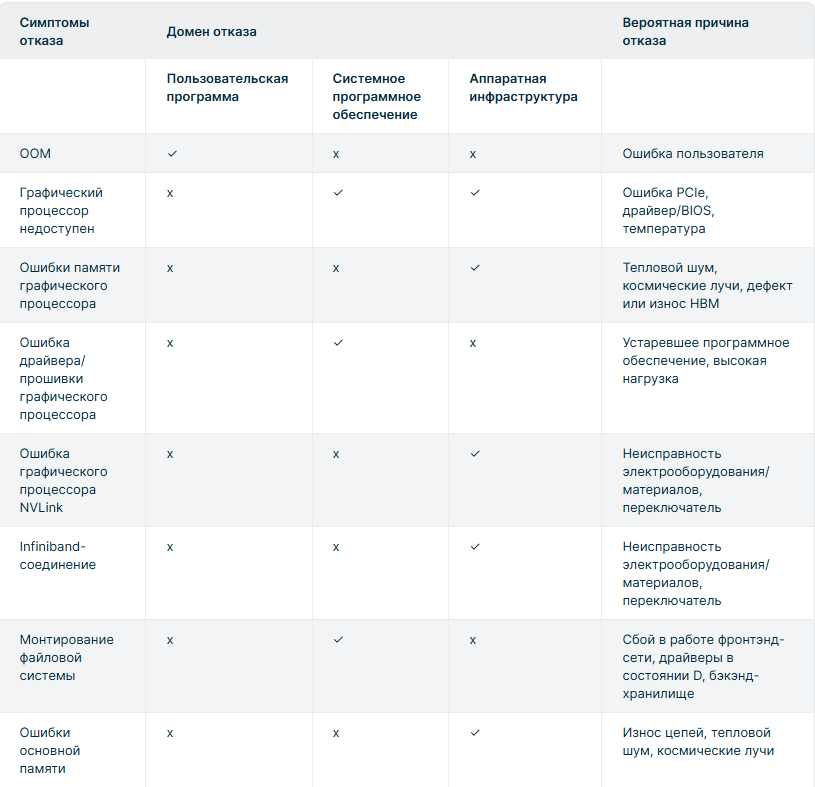
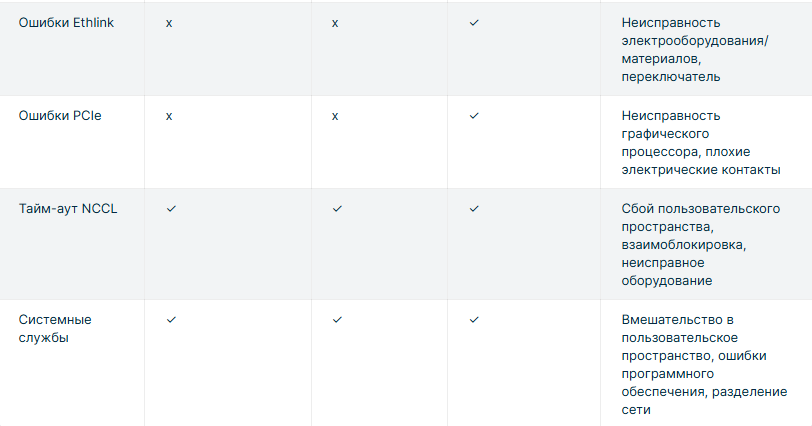 В то же время многие непредвиденные сбои на уровне инфраструктуры могут оставаться неясными для операторов кластера и не могут быть однозначно отнесены к их причине, что препятствует эффективному устранению неполадок. Поэтому критически важными становятся детальное наблюдение и проактивный мониторинг работоспособности. Важность отслеживания фактического использования графического процессора При крупномасштабном обучении машинного обучения использование графических процессоров не обязательно означает, что они способствуют реальному прогрессу разработки модели. Кластер может казаться загруженным, пока задания перезапускаются, находятся в очередях или восстанавливаются после сбоев. Перерывы в выполнении заданий увеличивают общее время обучения, добавляя дополнительное время ненужного использования ресурсов графических процессоров, когда эти вычислительные блоки простаивают для обучения модели. Чтобы увидеть, насколько эффективно мы используем зарезервированное время графического процессора, мы можем отслеживать полезную производительность — отношение времени вычислений, потраченного на достижение фактического прогресса в задаче машинного обучения, к общему времени обучения. Есть разные определения полезной производительности и несколько относительно близких терминов, описывающих использование вычислений кластера, такие как коэффициент эффективного времени обучения (ETTR) или использование FLOPs модели (MFU), которые мы не рассматриваем в этой статье.
В то же время многие непредвиденные сбои на уровне инфраструктуры могут оставаться неясными для операторов кластера и не могут быть однозначно отнесены к их причине, что препятствует эффективному устранению неполадок. Поэтому критически важными становятся детальное наблюдение и проактивный мониторинг работоспособности. Важность отслеживания фактического использования графического процессора При крупномасштабном обучении машинного обучения использование графических процессоров не обязательно означает, что они способствуют реальному прогрессу разработки модели. Кластер может казаться загруженным, пока задания перезапускаются, находятся в очередях или восстанавливаются после сбоев. Перерывы в выполнении заданий увеличивают общее время обучения, добавляя дополнительное время ненужного использования ресурсов графических процессоров, когда эти вычислительные блоки простаивают для обучения модели. Чтобы увидеть, насколько эффективно мы используем зарезервированное время графического процессора, мы можем отслеживать полезную производительность — отношение времени вычислений, потраченного на достижение фактического прогресса в задаче машинного обучения, к общему времени обучения. Есть разные определения полезной производительности и несколько относительно близких терминов, описывающих использование вычислений кластера, такие как коэффициент эффективного времени обучения (ETTR) или использование FLOPs модели (MFU), которые мы не рассматриваем в этой статье. 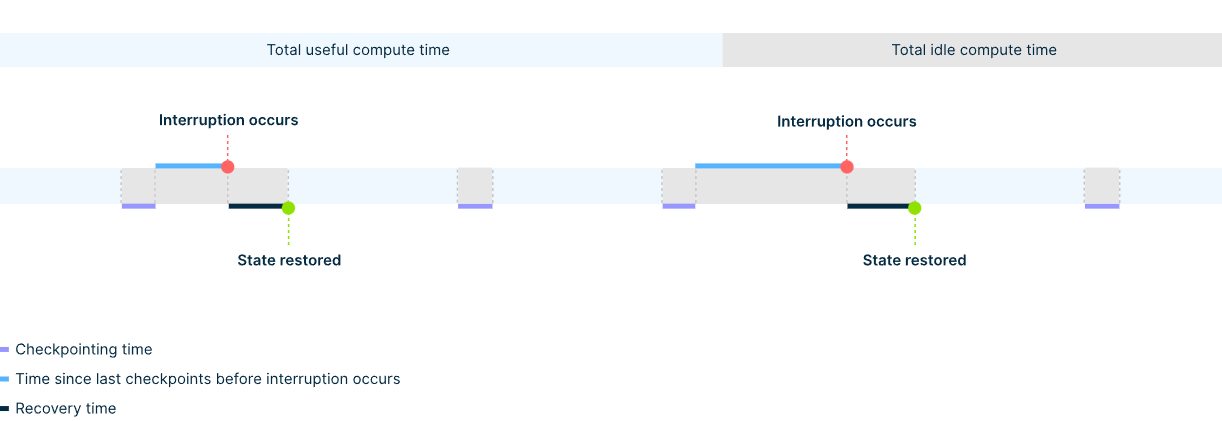 Если исключить из уравнения запланированную настройку кластера и время его обслуживания, то основным фактором, влияющим на показатель полезной производительности, будет время простоя вычислений, связанное с надежностью, вызванное прерываниями заданий и контрольными точками. Согласно рисунку 1, мы можем рассчитать процент полезной производительности по следующей формуле: Goodput = Useful compute time / (Useful compute time + Idle compute time)где Idle compute time состоит из: Время создания контрольной точки: процесс также занимает время и приводит к кратковременному прерыванию выполнения. Возможная потеря времени при использовании хранилища, оптимизированного для ИИ, может составить до одной минуты.Потеря времени обучения с последней контрольной точки: каждая ошибка сводит на нет прогресс, достигнутый с момента последней контрольной точки. Возможная потеря до нескольких часов (в зависимости от частоты контрольных точек).Время восстановления после сбоев: системе требуется время для обнаружения сбоя и запуска процесса восстановления, который включает замену узла, перезапуск задания и инициализацию модели. Потенциальные потери могут составлять от десятков минут до нескольких часов (в зависимости от уровня автоматизации).Такой подход наглядно демонстрирует, как показатели надёжности могут влиять на эффективность инвестиций в инфраструктуру ИИ и рентабельность продуктов ИИ. Сокращение времени простоя кластера графических процессоров приводит к ускорению разработки моделей, сокращению времени вывода продуктов на рынок и освобождению ресурсов кластера для дополнительных экспериментов. Как мы измеряем надежность кластеров ИИ В то время как метрика полезной производительности количественно оценивает влияние низкой надежности кластера на бизнес, другие ключевые метрики предоставляют инженерам полезную информацию для повышения надежности инфраструктуры ИИ: среднее время между отказами (MTBF), среднее время до отказа (MTTF) и среднее время восстановления (MTTR).
Если исключить из уравнения запланированную настройку кластера и время его обслуживания, то основным фактором, влияющим на показатель полезной производительности, будет время простоя вычислений, связанное с надежностью, вызванное прерываниями заданий и контрольными точками. Согласно рисунку 1, мы можем рассчитать процент полезной производительности по следующей формуле: Goodput = Useful compute time / (Useful compute time + Idle compute time)где Idle compute time состоит из: Время создания контрольной точки: процесс также занимает время и приводит к кратковременному прерыванию выполнения. Возможная потеря времени при использовании хранилища, оптимизированного для ИИ, может составить до одной минуты.Потеря времени обучения с последней контрольной точки: каждая ошибка сводит на нет прогресс, достигнутый с момента последней контрольной точки. Возможная потеря до нескольких часов (в зависимости от частоты контрольных точек).Время восстановления после сбоев: системе требуется время для обнаружения сбоя и запуска процесса восстановления, который включает замену узла, перезапуск задания и инициализацию модели. Потенциальные потери могут составлять от десятков минут до нескольких часов (в зависимости от уровня автоматизации).Такой подход наглядно демонстрирует, как показатели надёжности могут влиять на эффективность инвестиций в инфраструктуру ИИ и рентабельность продуктов ИИ. Сокращение времени простоя кластера графических процессоров приводит к ускорению разработки моделей, сокращению времени вывода продуктов на рынок и освобождению ресурсов кластера для дополнительных экспериментов. Как мы измеряем надежность кластеров ИИ В то время как метрика полезной производительности количественно оценивает влияние низкой надежности кластера на бизнес, другие ключевые метрики предоставляют инженерам полезную информацию для повышения надежности инфраструктуры ИИ: среднее время между отказами (MTBF), среднее время до отказа (MTTF) и среднее время восстановления (MTTR). 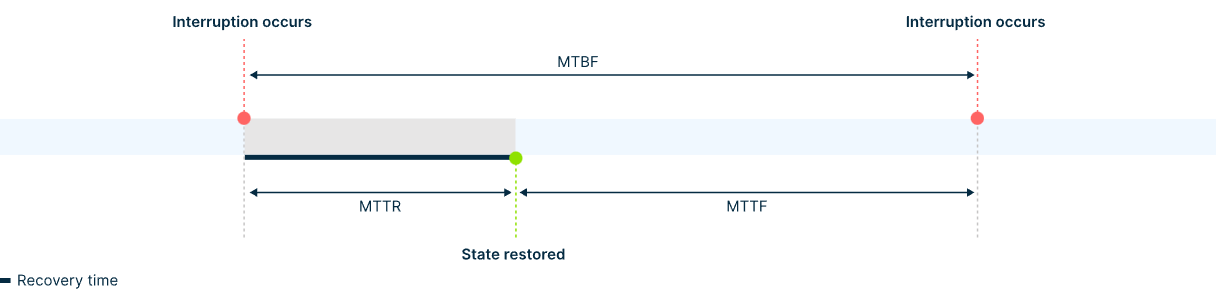 В Nebius мы уделяем особое внимание показателям MTBF и MTTR, чтобы отслеживать ход наших постоянных усилий по улучшению стабильности кластера. MTBF: как часто происходят отказы MTBF измеряет время работы кластера до возникновения сбоя. Мы выражаем его в часах работы графических процессоров (GPU) — общем времени безотказной работы всех графических процессоров кластера, делённом на количество сбоев, связанных с инфраструктурой (например, сбои GPU, ошибки PCIe, сбои сети). Среднее время безотказной работы =Number of GPUs * Operational time / Number of infra failures Например, кластер из 1024 графических процессоров, работающий в течение 336 часов с 13 сбоями инфраструктуры, даёт среднее время безотказной работы (MTBF) 26 446 графических процессоров-часов. Чтобы перевести эту метрику в обычные часы, нужно просто разделить значение на количество графических процессоров в кластере, что составляет около 25,8 часов. Мы используем показатель MTBF для отслеживания стабильности нашей инфраструктуры. Рост MTBF указывает на повышение надежности компонентов, улучшение работы встроенного ПО или драйверов, а также на успешные стратегии профилактики (например, более разумное планирование задач или контроль работоспособности). И наоборот, снижение MTBF указывает на ухудшение качества обслуживания клиентов и надежности кластера. Чем выше среднее время безотказной работы (MTBF), тем меньше перезапусков задания, меньше вычислительных ресурсов тратится впустую и тем более плавным становится жизненный цикл обучения ИИ. MTTR: Как быстро восстанавливается система MTTR измеряет среднее время, необходимое для обнаружения, изоляции и устранения сбоев инфраструктуры, возвращая затронутый узел или сегмент кластера в работоспособное, планируемое состояние. MTTR =Total resolution time / Number of infra failures Общее время устранения неполадки включает все этапы по замене неисправного узла и предоставлению готового к использованию работоспособного узла: изоляция узла, предоставление запасного узла и повторное присоединение состояния (например, драйверов, среды, кластерной структуры). Как мы обеспечиваем надежность кластеров ИИ в Nebius Обеспечение надежности кластера ИИ — многоуровневая задача, требующая тесной координации инженерных усилий по всему комплексу инфраструктуры. В Nebius мы создаём вертикально интегрированное облако ИИ, обеспечивая оптимальную настройку и согласованность каждого компонента этого комплекса для обеспечения надёжности системы. Мы можем выделить пять основных компонентов с автоматизацией на каждом этапе, которые составляют наш подход к созданию предсказуемой и стабильной среды для крупномасштабного распределённого обучения. Многоэтапные приемочные испытанияПассивные и активные проверки здоровьяИзоляция и миграция рабочей нагрузкиЗамена узла и восстановление состоянияСквозное наблюдение и проактивные уведомленияДавайте подробнее рассмотрим каждый из этих методов обеспечения надежности. Многоэтапные приемочные испытания У нас есть уникальная возможность повысить надежность кластера уже на начальном этапе — путем проектирования серверных компонентов, разработки фирменных прошивок и осуществления тщательного контроля на площадке контрактного производства. Заводские испытания на месте Сначала тестирование начинается на заводе, сразу после сборки сервера. Мы тестируем производительность каждого серверного узла, гарантируя, что он покинет завод только в том случае, если все его компоненты, от системы охлаждения и блока питания до производительности графического процессора и NVMe, работают ожидаемым образом. Термическая стабильность: gpu_burn стресс-тестPower stress: импульсная нагрузка на графический процессор для проверки способности блока питания выдерживать пиковые нагрузкиДиагностика NVIDIA: DCGM -4 (8–12 часов с плагином EUD) и т. д.Тесты производительности: ядра SuperBench, NCCL, HPL (LINPACK) и собственный обучающий тест LLM на основе JAX от NebiusФоновый мониторинг: dmesg, обнаружение перебоев в работе Ethernet/IB-соединения, журналы системных ошибок Тесты развертывания узлов После развёртывания оборудования на площадке дата-центра мы проводим следующий этап тестирования перед первой загрузкой узла или после его повторного развёртывания после устранения неполадок. Этот этап тестирования позволяет убедиться в стабильной работе узла перед его добавлением в кластерную сеть. Диагностика DCGM: запустите dcgmi diag -4 с плагином EUD в 30-минутном цикле для проверки графического процессора, PCIe, питания и тепловой стабильности.Фоновый мониторинг: отслеживание dmesg, счетчиков Ethernet/IB и стабильности соединения во время всех тестов.Gpu_burn + NCCL p2pBandwidth: стрессовая проверка графических процессоров и проверка пропускной способности межсоединенийSuperBench: выполнение набора тестов производительности вычислений, памяти и связи (GEMM, gpu-copy, mem-bw, nccl-bw, вывод ORT/TensorRT и т. д.)Тест Nebius LLM: запуск обучения MoE на базе JAX для проверки готовности к сквозной рабочей нагрузкеДиагностика партнеров (NVIDIA Field Diagnostics): расширенная диагностика графического процессора NVIDIA Тесты виртуальной платформы Мы проводим диагностические тесты на уровне виртуализации для образов виртуальных машин, узлов и кластерной структуры, гарантируя надежную работу облачной среды при интенсивных рабочих нагрузках. Пассивные проверки Работоспособность экземпляра/формы: проверка состояния виртуальной машины, типа платформы (H100/H200/L40S/B200), количества графических процессоров, настроек InfiniBand, IP-адреса SSH.Конфигурация Virt/PCIe: проверьте MaxReadReq, устройство pvpanic, настройки PCIeСостояние графического процессора NVIDIA: подтверждение количества графических процессоров, режима ECC, версии VBIOSСостояние структуры: проверка топологии NVLink/PCIe, обнаружение DCGMРаботоспособность InfiniBand: обеспечение правильного количества устройств CX7, активных портов, согласованности прошивки и ключей pkeys.Проводка для наблюдения: проверка токена IAM, плотности метрик, сбор журналов агентаАктивные проверки Диагностика DCGMI (уровень 2): 11-минутный стресс-тест GPU, PCIe, NVLinkПримеры CUDA: deviceQuery, vectorAdd, multiGPU, P2P, тесты пропускной способностиПропускная способность копирования SuperBench: проверка пропускной способности графического процессора ↔ центрального процессора в сравнении с пороговыми значениямиOSU MPI: проверка работоспособности osu_hello / osu_initNCCL all-reduce: коллективная проверка пропускной способности внутри хоста GPUКольцо NCCL через InfiniBand: проверка транспорта InfiniBand с помощью кольцевого алгоритма Предварительные кластерные тесты Наконец, мы запускаем несколько проверок и тестов, аналогичных производственным (например, тесты NVIDIA DGX), чтобы убедиться, что кластер соответствует всем целевым показателям производительности и полностью стабилен для распределенных рабочих нагрузок ИИ. Коллективы NCCL: проверка работоспособности сети InfiniBand, обнаружение неисправных или ухудшенных соединенийОбучение MLPerf: оценка распределенных учебных рабочих нагрузок для производительности графических процессоров и межсоединенийТесты NVIDIA DGX: сравните производительность кластера со стандартными для отрасли рабочими нагрузкамиGPU Fryer: проверка графических процессоров на стрессоустойчивость для обнаружения аномального теплового дросселирования или ухудшения характеристикHPL (LINPACK): сильно нагружает графические процессоры; чувствителен к потере пакетов и нестабильности соединенийInfiniBand Ring / All-to-All (без NVLink): проверка стабильности соединения InfiniBand при коллективной связиClusterKit: запустите NVIDIA IB bring-up suite для проверки пропускной способности и задержки.Проверки топологии InfiniBand: проверка соединений «ядро-позвоночник-лист» и назначений рельсов через API UFM; без расхожденийHPL на группах хостов: запуск на подмножествах из 8, 16 и 32 узлов; требуется отклонение производительности <1%NCCL в группах хостов: то же, что и выше, тестирование коллективов на узлах POD/CoreДлительная диагностика DCGM: запуск расширенных 8–12-часовых стресс-тестов графического процессора с плагином EUD для всех POD; все должны пройти успешноGpu_burn: проверка термостабильности на уровне стойки; перегрев не допускаетсяИмпульсный тест графического процессора: подайте одновременную импульсную нагрузку на узел/стойку; блок питания должен выдерживать пиковую мощность Только после успешного прохождения всех этих испытаний мы выпускаем оборудование в эксплуатацию. Эти первоначальные инвестиции помогают нам предотвращать сбои, увеличивая среднее время безотказной работы и обеспечивая стабильную производительность с первого дня. Пассивные и активные проверки здоровья При запуске кластера первым шагом для обеспечения его надёжности является как можно более раннее выявление проблемы. Для этого мы проводим комплексные проверки работоспособности. Они помогают нам определить, какие узлы кластера недостаточно работоспособны для планирования задач и постановки их в очередь. Почему это важно? Выявление проблем: благодаря комплексным проверкам работоспособности системы, как правило, достаточно всего нескольких секунд, чтобы выявить проблемы и минимизировать сбои в работе. Для сравнения, без проверок работоспособности системы проблемы можно выявить только в случае сбоя работы под нагрузкой. Определение первопричины: при правильной настройке проверки работоспособности причины проблем отображаются мгновенно, что помогает выявить их и устранить. Без проверки работоспособности определение причины сбоев узлов может быть сложной задачей и потребовать многочасового исследования. Мы разработали набор пассивных и активных проверок работоспособности, которые непрерывно работают в фоновом режиме и контролируют все критически важные компоненты системы: графические процессоры, системное программное обеспечение, сетевые соединения и многое другое. Пассивные проверки здоровья Пассивные проверки работоспособности непрерывно собирают, обобщают и анализируют данные в фоновом режиме. Они предназначены для раннего выявления признаков ухудшения работы или сбоя без ущерба для рабочих нагрузок. Ниже приведены некоторые примеры параметров, которые мы отслеживаем с помощью пассивных проверок работоспособности. Аппаратное обеспечение и драйвер графического процессора Согласованность версий драйверов и библиотек (CUDA, NCCL и т.д.)Обнаружение ошибок ECC (код исправления ошибок)Мониторинг температуры и оповещения о дросселированииМониторинг состояния электропитания и отслеживание использованияОтчеты об ошибках XID/SXID (коды исключений графического процессора)Состояние шины PCIe и состояние питанияСеть InfiniBand Проверка статуса соединения (обнаружение работоспособности/неработоспособности)Счетчики аппаратных ошибок (например, повторные попытки, CRC, потерянные пакеты)Система и топология Использование диска и доступная емкостьТопология NVLink: наличие, количество активных соединений, состояние пропускной способностиОтслеживание работоспособности коллективов NCCL (например, тайм-ауты, зависания) Активные проверки здоровья Активные проверки работоспособности выполняются во время определённых событий жизненного цикла кластера или в периоды простоя. Они заблаговременно выявляют неисправности до планирования заданий, помогая предотвратить перерывы в обучении и повысить общую надёжность. Эта функция включена по умолчанию в кластерах на базе Soperator и доступна в режиме предварительного просмотра для управляемых сред Kubernetes по запросу. DCGM diag 2, 3: Запуск диагностики графического процессора NVIDIA (быстрая в r2, расширенный стресс-тест в r3) для проверки состояния питания, памяти, PCIe и температуры, выявляя как общие, так и скрытые неисправности оборудования.Производительность All-Reduce на одном узле (тест NCCL с NVLink): запускает NCCL All-Reduce на каждом узле для проверки высокопроизводительной связи между графическими процессорами с использованием NVLink.Производительность All-Reduce с одним узлом (тест NCCL с Infiniband): выполняет тот же тест All-Reduce, принудительно использующий Infiniband вместо NVLink.Производительность All-Reduce в многоузловой среде (тест NCCL с NVLink и Infiniband): выполняет распределенный тест All-Reduce, который проверяет связь NVLink между графическими процессорами в пределах одного узла и связь Infiniband в пределах разных узлов.ib_write_bw / ib_write_lat (GPU Target): измеряет пропускную способность InfiniBand и задержку между графическими процессорами через RDMA для обеспечения оптимальной производительности межузловой сети GPU.ib_write_bw / ib_write_lat (ЦП Целевой): Тестирует скорость InfiniBand из памяти ЦП для выявления узких мест или нестабильности сети, связанных с PCIe или сетевым адаптером.GPU-fryer: подвергает стрессу вычисления и память графического процессора для обнаружения тепловой нестабильности, дросселирования или деградации кремния при полной нагрузке.Проверка пропускной способности памяти (membw): измеряет пропускную способность памяти (GPU HBM или CPU DRAM) для проверки работоспособности подсистемы памяти и выявления неисправностей, ограничивающих пропускную способность.Обучение модели МО: запускает небольшое распределенное задание по обучению, чтобы проверить, что графические процессоры, сетевые соединения, контейнеры и планирование работают сквозным образом, как в производственной среде. Изоляция рабочей нагрузки и предотвращение сбоев в работе После выявления проблемы следующим шагом является изоляция неисправного узла от доступности по расписанию и предотвращение каскадных сбоев заданий. Кроме того, нам необходимо минимизировать влияние на текущую рабочую нагрузку клиента, чтобы предотвратить сбои заданий. Ниже представлено описание нашего подхода. Критические неисправности Система автоматически отключает неработоспособные узлы, удаляя их из пула планирования, позволяя при возможности завершить текущие задания. Такой подход исключает каскадные сбои заданий, а отключённые узлы отключаются за считанные секунды без какого-либо ручного вмешательства, как и в случае неавтоматизированного потока.Система отправляет сигнал «экстренной контрольной точки» в систему обучения клиента, побуждая её сохранить ход выполнения задания перед его завершением. Это может сэкономить часы обучения. Эта функция появится в ближайшее время.При проблемах с сетевым подключением система перенаправляет соединение (например, AllReduce) затронутого узла через исправные каналы. Это может привести к временному снижению производительности, но предотвращает сбои заданий и потерю прогресса обучения. Эта функция появится в ближайшее время. Некритические неисправности Система помечает затронутый узел для упреждающего устранения неполадок, не влияя на текущие рабочие нагрузки. «Мы экспериментируем с TorchFT, новая библиотека PyTorch, обеспечивающая отказоустойчивость на каждом этапе распределенного обучения. В отличие от традиционных схем, TorchFT позволяет продолжать обучение даже при отказе отдельных узлов или графических процессоров, избегая полного перезапуска задания. Несмотря на то, что TorchFT все еще находится в стадии развития, он демонстрирует высокий потенциал для крупномасштабного обучения LLM и рабочих нагрузок, требующих высокой отказоустойчивости. Если вы заинтересованы во внедрении TorchFT, мы будем рады поддержать интеграцию и поделиться некоторыми идеями». Замена узла и восстановление состояния Когда неисправный узел выключается и переходит в режим ожидания, наши механизмы оркестровки автоматически заменяют его исправным резервным. Мы создаём выделенный резервный буфер графических процессоров для каждого клиента, чтобы обеспечить быстрое выделение ресурсов для нового узла и исключить риск его простоя из-за нехватки ресурсов. Новый узел автоматически появляется в кластере со всеми предустановленными драйверами и зависимостями, готовясь к работе сразу после выделения ресурсов. Благодаря полной автоматизации в Nebius эта задача занимает считанные минуты.вместо часов с ручным вмешательством. Сквозное наблюдение и проактивные уведомления Важная составляющая надёжности — это наблюдаемость. Прозрачность инфраструктуры — ключ к отличному клиентскому опыту. У нас есть различные уровни наблюдения: системные метрики, контроль работоспособности и т. д. Давайте рассмотрим стек контроля работоспособности для Soperator, нашего управляемого оркестратора на базе Slurm. Мониторинг заданий: мы предоставляем обобщенную информацию о заданиях в кластере, что позволяет вам выбрать задание для детального изучения.Мониторинг рабочих узлов: вы также можете просматривать агрегированную информацию и отдельные сведения по рабочим узлам. Здесь регистрируются все сбои инфраструктуры кластера с указанием причин (например, XID графического процессора, проблемы с IB и т. д.). Вы можете определить причины сбоя задания, а также проверить, устранены ли какие-либо проблемы кластера или продолжают ли они решаться.Общее состояние кластера: содержит всю информацию, связанную с состоянием работоспособности графического процессора, центрального процессора и хранилища. Кроме того, мы заблаговременно уведомляем клиентов о проблемах с кластерами, плановом техническом обслуживании и сбоях в работе, чтобы предотвратить скрытые сбои и потерю времени. У нас есть специальный канал Slack для интеграции с нашими клиентами для быстрого, эффективного и удобного общения. Клиенты могут настраивать уведомления о таких событиях, как: Оповещения о прерываниях в режиме реального времени: мгновенные уведомления о сбоях или задержках учебных заданий. Выявлены критические проблемы со здоровьем, которые могут повлиять на рабочую нагрузку.Обнаружение ухудшения производительности: выявляйте скрытые проблемы, связанные со снижением производительности, и уведомляйте о них. Эта функция появится в ближайшее время.Без надлежащего контроля анализ сбоев в работе отнимает часы ценного рабочего времени инженера машинного обучения. Благодаря интегрированным панелям управления и уведомлениям в режиме реального времени мы сокращаем время устранения неполадок с нескольких часов до нескольких минут, обеспечивая мгновенное понимание первопричин сбоев. Проверенная в боях надежность для производственных кластеров ИИ Благодаря нашим уникальным стратегиям управления сбоями мы можем предоставить нашим клиентам надежную ИИ-инфраструктуру для крупномасштабных распределенных рабочих нагрузок, а также сократить потери времени и средств, связанные с перерывами в обучении. Синтетические бенчмарки не могут полностью охватить поведение крупномасштабных кластеров ИИ под реальными рабочими нагрузками. Для получения более реалистичной картины мы также измеряем надёжность клиентских производственных сред, в которых проводится интенсивное распределённое обучение. В начале статьи мы упомянули анонимного клиента, который запустил несколько заданий обучения LLM на кластере из 3000 графических процессоров (375 узлов). Эта система достигла пикового среднего времени безотказной работы (MTBF) 56,6 часа (169 800 часов работы GPU), при среднем показателе 33,0 часа за последние несколько недель. Хотя каждая учебная среда уникальна, и выводы об одном кластере нельзя напрямую применить к другому, мы видим, как надежность кластера приводит к уменьшению количества прерываний и уменьшению затрат, требуемых от команд машинного обучения при масштабном обучении. Когда дело доходит до способности кластера восстанавливать свое состояние, мы достигаем среднего среднего времени восстановления (MTTR) 12 минут на большинстве наших установокЭтот впечатляющий результат стал возможен благодаря сквозной автоматизации процесса восстановления: от ранней диагностики неисправностей до развертывания заменяющих узлов без вмешательства человека. Поскольку задачи обучения распределены по сотням графических процессоров, даже небольшие сбои могут сбить графики поставок. Стабильность, которую мы получаем от кластеров Nebius, позволяет нам планировать масштабные эксперименты без постоянной корректировки возможных сбоевДрю Джэгл, руководитель отдела искусственного интеллекта в Captions Мы считаем, что представленные выше показатели надёжности говорят сами за себя, но создание устойчивой инфраструктуры ИИ — это гораздо больше, чем просто цифры. Это непрерывный процесс. Именно поэтому мы разрабатываем и постоянно совершенствуем целый комплекс механизмов для раннего обнаружения сбоев, быстрого восстановления и поддержания работы кластеров с минимальными перебоями — даже в сложных условиях масштабного и длительного обучения. Наша цель — повысить производительность и помочь вам получить максимальную отдачу от инвестиций в инфраструктуру ИИ.Высокая доступность в любом масштабе сокращает незапланированные перерывы, сокращает циклы восстановления и позволяет командам сосредоточиться на выполнении своей работы, а не на управлении инцидентами. Если вы ищете надежное облако, специально разработанное для крупномасштабного обучения искусственного интеллекта, или просто хотите узнать больше о нашей платформе, свяжитесь с нами studio.nebius.com/playground console.nebius.com nebius.com...
В Nebius мы уделяем особое внимание показателям MTBF и MTTR, чтобы отслеживать ход наших постоянных усилий по улучшению стабильности кластера. MTBF: как часто происходят отказы MTBF измеряет время работы кластера до возникновения сбоя. Мы выражаем его в часах работы графических процессоров (GPU) — общем времени безотказной работы всех графических процессоров кластера, делённом на количество сбоев, связанных с инфраструктурой (например, сбои GPU, ошибки PCIe, сбои сети). Среднее время безотказной работы =Number of GPUs * Operational time / Number of infra failures Например, кластер из 1024 графических процессоров, работающий в течение 336 часов с 13 сбоями инфраструктуры, даёт среднее время безотказной работы (MTBF) 26 446 графических процессоров-часов. Чтобы перевести эту метрику в обычные часы, нужно просто разделить значение на количество графических процессоров в кластере, что составляет около 25,8 часов. Мы используем показатель MTBF для отслеживания стабильности нашей инфраструктуры. Рост MTBF указывает на повышение надежности компонентов, улучшение работы встроенного ПО или драйверов, а также на успешные стратегии профилактики (например, более разумное планирование задач или контроль работоспособности). И наоборот, снижение MTBF указывает на ухудшение качества обслуживания клиентов и надежности кластера. Чем выше среднее время безотказной работы (MTBF), тем меньше перезапусков задания, меньше вычислительных ресурсов тратится впустую и тем более плавным становится жизненный цикл обучения ИИ. MTTR: Как быстро восстанавливается система MTTR измеряет среднее время, необходимое для обнаружения, изоляции и устранения сбоев инфраструктуры, возвращая затронутый узел или сегмент кластера в работоспособное, планируемое состояние. MTTR =Total resolution time / Number of infra failures Общее время устранения неполадки включает все этапы по замене неисправного узла и предоставлению готового к использованию работоспособного узла: изоляция узла, предоставление запасного узла и повторное присоединение состояния (например, драйверов, среды, кластерной структуры). Как мы обеспечиваем надежность кластеров ИИ в Nebius Обеспечение надежности кластера ИИ — многоуровневая задача, требующая тесной координации инженерных усилий по всему комплексу инфраструктуры. В Nebius мы создаём вертикально интегрированное облако ИИ, обеспечивая оптимальную настройку и согласованность каждого компонента этого комплекса для обеспечения надёжности системы. Мы можем выделить пять основных компонентов с автоматизацией на каждом этапе, которые составляют наш подход к созданию предсказуемой и стабильной среды для крупномасштабного распределённого обучения. Многоэтапные приемочные испытанияПассивные и активные проверки здоровьяИзоляция и миграция рабочей нагрузкиЗамена узла и восстановление состоянияСквозное наблюдение и проактивные уведомленияДавайте подробнее рассмотрим каждый из этих методов обеспечения надежности. Многоэтапные приемочные испытания У нас есть уникальная возможность повысить надежность кластера уже на начальном этапе — путем проектирования серверных компонентов, разработки фирменных прошивок и осуществления тщательного контроля на площадке контрактного производства. Заводские испытания на месте Сначала тестирование начинается на заводе, сразу после сборки сервера. Мы тестируем производительность каждого серверного узла, гарантируя, что он покинет завод только в том случае, если все его компоненты, от системы охлаждения и блока питания до производительности графического процессора и NVMe, работают ожидаемым образом. Термическая стабильность: gpu_burn стресс-тестPower stress: импульсная нагрузка на графический процессор для проверки способности блока питания выдерживать пиковые нагрузкиДиагностика NVIDIA: DCGM -4 (8–12 часов с плагином EUD) и т. д.Тесты производительности: ядра SuperBench, NCCL, HPL (LINPACK) и собственный обучающий тест LLM на основе JAX от NebiusФоновый мониторинг: dmesg, обнаружение перебоев в работе Ethernet/IB-соединения, журналы системных ошибок Тесты развертывания узлов После развёртывания оборудования на площадке дата-центра мы проводим следующий этап тестирования перед первой загрузкой узла или после его повторного развёртывания после устранения неполадок. Этот этап тестирования позволяет убедиться в стабильной работе узла перед его добавлением в кластерную сеть. Диагностика DCGM: запустите dcgmi diag -4 с плагином EUD в 30-минутном цикле для проверки графического процессора, PCIe, питания и тепловой стабильности.Фоновый мониторинг: отслеживание dmesg, счетчиков Ethernet/IB и стабильности соединения во время всех тестов.Gpu_burn + NCCL p2pBandwidth: стрессовая проверка графических процессоров и проверка пропускной способности межсоединенийSuperBench: выполнение набора тестов производительности вычислений, памяти и связи (GEMM, gpu-copy, mem-bw, nccl-bw, вывод ORT/TensorRT и т. д.)Тест Nebius LLM: запуск обучения MoE на базе JAX для проверки готовности к сквозной рабочей нагрузкеДиагностика партнеров (NVIDIA Field Diagnostics): расширенная диагностика графического процессора NVIDIA Тесты виртуальной платформы Мы проводим диагностические тесты на уровне виртуализации для образов виртуальных машин, узлов и кластерной структуры, гарантируя надежную работу облачной среды при интенсивных рабочих нагрузках. Пассивные проверки Работоспособность экземпляра/формы: проверка состояния виртуальной машины, типа платформы (H100/H200/L40S/B200), количества графических процессоров, настроек InfiniBand, IP-адреса SSH.Конфигурация Virt/PCIe: проверьте MaxReadReq, устройство pvpanic, настройки PCIeСостояние графического процессора NVIDIA: подтверждение количества графических процессоров, режима ECC, версии VBIOSСостояние структуры: проверка топологии NVLink/PCIe, обнаружение DCGMРаботоспособность InfiniBand: обеспечение правильного количества устройств CX7, активных портов, согласованности прошивки и ключей pkeys.Проводка для наблюдения: проверка токена IAM, плотности метрик, сбор журналов агентаАктивные проверки Диагностика DCGMI (уровень 2): 11-минутный стресс-тест GPU, PCIe, NVLinkПримеры CUDA: deviceQuery, vectorAdd, multiGPU, P2P, тесты пропускной способностиПропускная способность копирования SuperBench: проверка пропускной способности графического процессора ↔ центрального процессора в сравнении с пороговыми значениямиOSU MPI: проверка работоспособности osu_hello / osu_initNCCL all-reduce: коллективная проверка пропускной способности внутри хоста GPUКольцо NCCL через InfiniBand: проверка транспорта InfiniBand с помощью кольцевого алгоритма Предварительные кластерные тесты Наконец, мы запускаем несколько проверок и тестов, аналогичных производственным (например, тесты NVIDIA DGX), чтобы убедиться, что кластер соответствует всем целевым показателям производительности и полностью стабилен для распределенных рабочих нагрузок ИИ. Коллективы NCCL: проверка работоспособности сети InfiniBand, обнаружение неисправных или ухудшенных соединенийОбучение MLPerf: оценка распределенных учебных рабочих нагрузок для производительности графических процессоров и межсоединенийТесты NVIDIA DGX: сравните производительность кластера со стандартными для отрасли рабочими нагрузкамиGPU Fryer: проверка графических процессоров на стрессоустойчивость для обнаружения аномального теплового дросселирования или ухудшения характеристикHPL (LINPACK): сильно нагружает графические процессоры; чувствителен к потере пакетов и нестабильности соединенийInfiniBand Ring / All-to-All (без NVLink): проверка стабильности соединения InfiniBand при коллективной связиClusterKit: запустите NVIDIA IB bring-up suite для проверки пропускной способности и задержки.Проверки топологии InfiniBand: проверка соединений «ядро-позвоночник-лист» и назначений рельсов через API UFM; без расхожденийHPL на группах хостов: запуск на подмножествах из 8, 16 и 32 узлов; требуется отклонение производительности <1%NCCL в группах хостов: то же, что и выше, тестирование коллективов на узлах POD/CoreДлительная диагностика DCGM: запуск расширенных 8–12-часовых стресс-тестов графического процессора с плагином EUD для всех POD; все должны пройти успешноGpu_burn: проверка термостабильности на уровне стойки; перегрев не допускаетсяИмпульсный тест графического процессора: подайте одновременную импульсную нагрузку на узел/стойку; блок питания должен выдерживать пиковую мощность Только после успешного прохождения всех этих испытаний мы выпускаем оборудование в эксплуатацию. Эти первоначальные инвестиции помогают нам предотвращать сбои, увеличивая среднее время безотказной работы и обеспечивая стабильную производительность с первого дня. Пассивные и активные проверки здоровья При запуске кластера первым шагом для обеспечения его надёжности является как можно более раннее выявление проблемы. Для этого мы проводим комплексные проверки работоспособности. Они помогают нам определить, какие узлы кластера недостаточно работоспособны для планирования задач и постановки их в очередь. Почему это важно? Выявление проблем: благодаря комплексным проверкам работоспособности системы, как правило, достаточно всего нескольких секунд, чтобы выявить проблемы и минимизировать сбои в работе. Для сравнения, без проверок работоспособности системы проблемы можно выявить только в случае сбоя работы под нагрузкой. Определение первопричины: при правильной настройке проверки работоспособности причины проблем отображаются мгновенно, что помогает выявить их и устранить. Без проверки работоспособности определение причины сбоев узлов может быть сложной задачей и потребовать многочасового исследования. Мы разработали набор пассивных и активных проверок работоспособности, которые непрерывно работают в фоновом режиме и контролируют все критически важные компоненты системы: графические процессоры, системное программное обеспечение, сетевые соединения и многое другое. Пассивные проверки здоровья Пассивные проверки работоспособности непрерывно собирают, обобщают и анализируют данные в фоновом режиме. Они предназначены для раннего выявления признаков ухудшения работы или сбоя без ущерба для рабочих нагрузок. Ниже приведены некоторые примеры параметров, которые мы отслеживаем с помощью пассивных проверок работоспособности. Аппаратное обеспечение и драйвер графического процессора Согласованность версий драйверов и библиотек (CUDA, NCCL и т.д.)Обнаружение ошибок ECC (код исправления ошибок)Мониторинг температуры и оповещения о дросселированииМониторинг состояния электропитания и отслеживание использованияОтчеты об ошибках XID/SXID (коды исключений графического процессора)Состояние шины PCIe и состояние питанияСеть InfiniBand Проверка статуса соединения (обнаружение работоспособности/неработоспособности)Счетчики аппаратных ошибок (например, повторные попытки, CRC, потерянные пакеты)Система и топология Использование диска и доступная емкостьТопология NVLink: наличие, количество активных соединений, состояние пропускной способностиОтслеживание работоспособности коллективов NCCL (например, тайм-ауты, зависания) Активные проверки здоровья Активные проверки работоспособности выполняются во время определённых событий жизненного цикла кластера или в периоды простоя. Они заблаговременно выявляют неисправности до планирования заданий, помогая предотвратить перерывы в обучении и повысить общую надёжность. Эта функция включена по умолчанию в кластерах на базе Soperator и доступна в режиме предварительного просмотра для управляемых сред Kubernetes по запросу. DCGM diag 2, 3: Запуск диагностики графического процессора NVIDIA (быстрая в r2, расширенный стресс-тест в r3) для проверки состояния питания, памяти, PCIe и температуры, выявляя как общие, так и скрытые неисправности оборудования.Производительность All-Reduce на одном узле (тест NCCL с NVLink): запускает NCCL All-Reduce на каждом узле для проверки высокопроизводительной связи между графическими процессорами с использованием NVLink.Производительность All-Reduce с одним узлом (тест NCCL с Infiniband): выполняет тот же тест All-Reduce, принудительно использующий Infiniband вместо NVLink.Производительность All-Reduce в многоузловой среде (тест NCCL с NVLink и Infiniband): выполняет распределенный тест All-Reduce, который проверяет связь NVLink между графическими процессорами в пределах одного узла и связь Infiniband в пределах разных узлов.ib_write_bw / ib_write_lat (GPU Target): измеряет пропускную способность InfiniBand и задержку между графическими процессорами через RDMA для обеспечения оптимальной производительности межузловой сети GPU.ib_write_bw / ib_write_lat (ЦП Целевой): Тестирует скорость InfiniBand из памяти ЦП для выявления узких мест или нестабильности сети, связанных с PCIe или сетевым адаптером.GPU-fryer: подвергает стрессу вычисления и память графического процессора для обнаружения тепловой нестабильности, дросселирования или деградации кремния при полной нагрузке.Проверка пропускной способности памяти (membw): измеряет пропускную способность памяти (GPU HBM или CPU DRAM) для проверки работоспособности подсистемы памяти и выявления неисправностей, ограничивающих пропускную способность.Обучение модели МО: запускает небольшое распределенное задание по обучению, чтобы проверить, что графические процессоры, сетевые соединения, контейнеры и планирование работают сквозным образом, как в производственной среде. Изоляция рабочей нагрузки и предотвращение сбоев в работе После выявления проблемы следующим шагом является изоляция неисправного узла от доступности по расписанию и предотвращение каскадных сбоев заданий. Кроме того, нам необходимо минимизировать влияние на текущую рабочую нагрузку клиента, чтобы предотвратить сбои заданий. Ниже представлено описание нашего подхода. Критические неисправности Система автоматически отключает неработоспособные узлы, удаляя их из пула планирования, позволяя при возможности завершить текущие задания. Такой подход исключает каскадные сбои заданий, а отключённые узлы отключаются за считанные секунды без какого-либо ручного вмешательства, как и в случае неавтоматизированного потока.Система отправляет сигнал «экстренной контрольной точки» в систему обучения клиента, побуждая её сохранить ход выполнения задания перед его завершением. Это может сэкономить часы обучения. Эта функция появится в ближайшее время.При проблемах с сетевым подключением система перенаправляет соединение (например, AllReduce) затронутого узла через исправные каналы. Это может привести к временному снижению производительности, но предотвращает сбои заданий и потерю прогресса обучения. Эта функция появится в ближайшее время. Некритические неисправности Система помечает затронутый узел для упреждающего устранения неполадок, не влияя на текущие рабочие нагрузки. «Мы экспериментируем с TorchFT, новая библиотека PyTorch, обеспечивающая отказоустойчивость на каждом этапе распределенного обучения. В отличие от традиционных схем, TorchFT позволяет продолжать обучение даже при отказе отдельных узлов или графических процессоров, избегая полного перезапуска задания. Несмотря на то, что TorchFT все еще находится в стадии развития, он демонстрирует высокий потенциал для крупномасштабного обучения LLM и рабочих нагрузок, требующих высокой отказоустойчивости. Если вы заинтересованы во внедрении TorchFT, мы будем рады поддержать интеграцию и поделиться некоторыми идеями». Замена узла и восстановление состояния Когда неисправный узел выключается и переходит в режим ожидания, наши механизмы оркестровки автоматически заменяют его исправным резервным. Мы создаём выделенный резервный буфер графических процессоров для каждого клиента, чтобы обеспечить быстрое выделение ресурсов для нового узла и исключить риск его простоя из-за нехватки ресурсов. Новый узел автоматически появляется в кластере со всеми предустановленными драйверами и зависимостями, готовясь к работе сразу после выделения ресурсов. Благодаря полной автоматизации в Nebius эта задача занимает считанные минуты.вместо часов с ручным вмешательством. Сквозное наблюдение и проактивные уведомления Важная составляющая надёжности — это наблюдаемость. Прозрачность инфраструктуры — ключ к отличному клиентскому опыту. У нас есть различные уровни наблюдения: системные метрики, контроль работоспособности и т. д. Давайте рассмотрим стек контроля работоспособности для Soperator, нашего управляемого оркестратора на базе Slurm. Мониторинг заданий: мы предоставляем обобщенную информацию о заданиях в кластере, что позволяет вам выбрать задание для детального изучения.Мониторинг рабочих узлов: вы также можете просматривать агрегированную информацию и отдельные сведения по рабочим узлам. Здесь регистрируются все сбои инфраструктуры кластера с указанием причин (например, XID графического процессора, проблемы с IB и т. д.). Вы можете определить причины сбоя задания, а также проверить, устранены ли какие-либо проблемы кластера или продолжают ли они решаться.Общее состояние кластера: содержит всю информацию, связанную с состоянием работоспособности графического процессора, центрального процессора и хранилища. Кроме того, мы заблаговременно уведомляем клиентов о проблемах с кластерами, плановом техническом обслуживании и сбоях в работе, чтобы предотвратить скрытые сбои и потерю времени. У нас есть специальный канал Slack для интеграции с нашими клиентами для быстрого, эффективного и удобного общения. Клиенты могут настраивать уведомления о таких событиях, как: Оповещения о прерываниях в режиме реального времени: мгновенные уведомления о сбоях или задержках учебных заданий. Выявлены критические проблемы со здоровьем, которые могут повлиять на рабочую нагрузку.Обнаружение ухудшения производительности: выявляйте скрытые проблемы, связанные со снижением производительности, и уведомляйте о них. Эта функция появится в ближайшее время.Без надлежащего контроля анализ сбоев в работе отнимает часы ценного рабочего времени инженера машинного обучения. Благодаря интегрированным панелям управления и уведомлениям в режиме реального времени мы сокращаем время устранения неполадок с нескольких часов до нескольких минут, обеспечивая мгновенное понимание первопричин сбоев. Проверенная в боях надежность для производственных кластеров ИИ Благодаря нашим уникальным стратегиям управления сбоями мы можем предоставить нашим клиентам надежную ИИ-инфраструктуру для крупномасштабных распределенных рабочих нагрузок, а также сократить потери времени и средств, связанные с перерывами в обучении. Синтетические бенчмарки не могут полностью охватить поведение крупномасштабных кластеров ИИ под реальными рабочими нагрузками. Для получения более реалистичной картины мы также измеряем надёжность клиентских производственных сред, в которых проводится интенсивное распределённое обучение. В начале статьи мы упомянули анонимного клиента, который запустил несколько заданий обучения LLM на кластере из 3000 графических процессоров (375 узлов). Эта система достигла пикового среднего времени безотказной работы (MTBF) 56,6 часа (169 800 часов работы GPU), при среднем показателе 33,0 часа за последние несколько недель. Хотя каждая учебная среда уникальна, и выводы об одном кластере нельзя напрямую применить к другому, мы видим, как надежность кластера приводит к уменьшению количества прерываний и уменьшению затрат, требуемых от команд машинного обучения при масштабном обучении. Когда дело доходит до способности кластера восстанавливать свое состояние, мы достигаем среднего среднего времени восстановления (MTTR) 12 минут на большинстве наших установокЭтот впечатляющий результат стал возможен благодаря сквозной автоматизации процесса восстановления: от ранней диагностики неисправностей до развертывания заменяющих узлов без вмешательства человека. Поскольку задачи обучения распределены по сотням графических процессоров, даже небольшие сбои могут сбить графики поставок. Стабильность, которую мы получаем от кластеров Nebius, позволяет нам планировать масштабные эксперименты без постоянной корректировки возможных сбоевДрю Джэгл, руководитель отдела искусственного интеллекта в Captions Мы считаем, что представленные выше показатели надёжности говорят сами за себя, но создание устойчивой инфраструктуры ИИ — это гораздо больше, чем просто цифры. Это непрерывный процесс. Именно поэтому мы разрабатываем и постоянно совершенствуем целый комплекс механизмов для раннего обнаружения сбоев, быстрого восстановления и поддержания работы кластеров с минимальными перебоями — даже в сложных условиях масштабного и длительного обучения. Наша цель — повысить производительность и помочь вам получить максимальную отдачу от инвестиций в инфраструктуру ИИ.Высокая доступность в любом масштабе сокращает незапланированные перерывы, сокращает циклы восстановления и позволяет командам сосредоточиться на выполнении своей работы, а не на управлении инцидентами. Если вы ищете надежное облако, специально разработанное для крупномасштабного обучения искусственного интеллекта, или просто хотите узнать больше о нашей платформе, свяжитесь с нами studio.nebius.com/playground console.nebius.com nebius.com...
Экземпляры NVIDIA HGX B200 теперь доступны публично как самообслуживаемые ИИ-кластеры в облаке Nebius AI Cloud. Это означает, что любой может получить доступ к NVIDIA Blackwell — новейшему поколению платформы ускоренных вычислений NVIDIA — всего за несколько кликов и с помощью кредитной карты. nebius.com/self-service Nebius устраняет барьеры на пути к передовым вычислениям в области ИИ в рамках нашей стратегии демократизации ИИ. Никаких списков ожидания, долгосрочных обязательств, длительных циклов закупок или переговоров о продажах — только мгновенный доступ через нашу веб-консоль или API с оплатой по факту использования. Получите доступ к новейшим вычислениям ИИ с помощью всего лишь кредитной карты На выставке GTC в Париже мы объявили о том, что один из первых экземпляров GB200 NVL72 доступен для клиентов в Европе. Сегодня мы предоставляем экземпляры HGX B200 разработчикам ИИ любого масштаба через наш портал самообслуживания. Независимо от того, являетесь ли вы индивидуальным энтузиастом ИИ, инженером МО в крупной исследовательской группе или внедряете ИИ в корпоративном контексте, доступ к вычислениям NVIDIA B200 теперь стал проще, чем когда-либо. Наш ранний доступ к NVIDIA HGX B200 через Nebius AI Cloud позволил нам достичь новых высот оптимизации вывода. Первые результаты показали многообещающее повышение производительности — примерно в 3,5 раза более быстрый вывод для диффузионных моделей, что критически важно для удовлетворения растущих потребностей индустрии ИИ Кирилл Солодских, генеральный директор и соучредитель TheStage AI, платформы для ускорения вывода Кластеры Nebius, созданные с использованием искусственного интеллекта Мы поставляем экземпляры NVIDIA HGX B200 в составе Nebius AI Cloud — полнофункциональной ИИ-инфраструктуры, которую мы создали с нуля для интенсивных и масштабных рабочих нагрузок ИИ. Кластеры графических процессоров NVIDIA объединены неблокируемой инфраструктурой NVIDIA Quantum-2 InfiniBand и поставляются с предустановленными драйверами графического процессора и сети, а также программным обеспечением для оркестрации (Kubernetes или Slurm). NVIDIA HGX B200 поставляется на одной материнской плате с восемью графическими процессорами (тот же форм-фактор, что и у предыдущих моделей Hopper SXM), что позволяет легко интегрировать HGX B200 в серверные стойки Nebius, разработанные по индивидуальному заказу. Бескомпромиссная производительность Независимо от того, является ли это средой с одним хостом по требованию или зарезервированной установкой с тысячей графических процессоров, все кластеры ИИ в Nebius проходят трехэтапное приемочное тестирование. Мы осуществляем контроль качества на месте у контрактного производителя, проверяем узлы перед их развертыванием в наших дата-центрах, а затем проводим комплексное тестирование кластера перед передачей его клиентам. Это тщательное тестирование гарантирует соответствие производительности NVIDIA HGX B200 в Nebius собственным бенчмаркам NVIDIA. Будущее ИИ уже здесь. Доступно каждому. Независимо от того, являетесь ли вы индивидуальным исследователем или членом крупной корпоративной команды, вы получаете полностью протестированные и оптимизированные кластеры графических процессоров, индивидуально разработанную инфраструктуру и бескомпромиссную производительность, которая гарантирует, что ваши рабочие нагрузки ИИ будут выполняться именно так, как и ожидалось. Будущее развития искусственного интеллекта уже наступило, и оно доступно по запросу. Доступ к NVIDIA HGX B200 систем сегодня через нашу веб-консоль или API. auth.nebius.com/ui/login...